This blog series demonstrates how to build an end-to-end ADF pipeline for extracting data from Azure SQL DB/Azure Data Lake Store and load to a star-schema data warehouse database with considerations of SCD (slow changing dimensions) and incremental loading.
The final pipeline will look as:
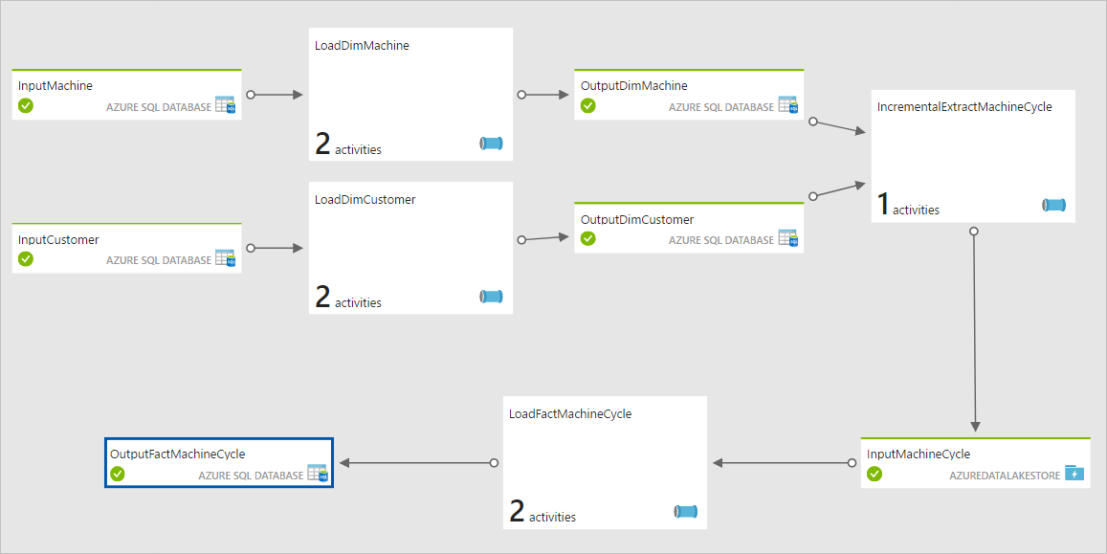
The machine cycle records will be load from the csv files stored in a Azure Data Lake store, and the reference data of customers and machines will be load form the Reference DB (Azure SQL DB). The ADF pipeline will first load the data into the staging tables in the target DW, and the ADF pipeline will then execute the SQL stored procedures to transform the data into star schema and implement the type 2 SCD.
A number of services within the Azure Cortana Intelligence Suite will be employed to build the end-to-end pipeline, including Azure Data Factory, Azure Data Lake Store, Azure Data Lake Analytics (U-SQL), Azure SQL Database, and the development tools (Visual Studio + SSDT). Four Visual Studio projects will be created, including the ReferenceDB for provisioning the Azure SQL reference database, the DW for provisioning the target Data Wareshourse, the ADLA for incrementally extracting the machine cycle data, and the ADF for the build of the pipeline. You can download the source code here.




This blog post covers the first part of the series to give a brief introduction of the example used in this demonstration and provides the steps for preparing the required demo databases/data lake directory and the sample data.
- Introduction & Preparation
- Build ADF pipelins for dimensional tables ELT
- Build ADLA U-SQL job for incremental extraction of machine cycle data
- Extend the ADF pipeline for facts table ELT
Preparation
1.Create Visual Studio solution
Create a Visual Studio solution with the SSDT tool to host all the projects required in this demonstration, including the DB projects for ReferenceDB and the target DW, and the ADF project.
2. Create ReferenceDB project

Create ReferenceDB project and add the scripts for creating Customer table and Machine table.
Customer table:
CREATE TABLE [dbo].[Customer]
(
[Id] INT NOT NULL PRIMARY KEY IDENTITY,
[Code] VARCHAR(10) NOT NULL,
[Name] VARCHAR(50) NOT NULL,
[LastModified] DATETIME2 NOT NULL
)
Machine table:
CREATE TABLE [dbo].[Machine]
(
[Id] INT NOT NULL PRIMARY KEY IDENTITY,
[Code] VARCHAR(10) NOT NULL,
[Name] VARCHAR(50) NOT NULL,
[Condition] VARCHAR(10) NOT NULL,
[LastModified] DATETIME2 NOT NULL
)
Create a post deployment script to add the sample data:
INSERT INTO [dbo].[Customer]
([Code]
,[Name]
,[LastModified])
VALUES
('C0001','Customer1', '2017-11-08 21:21:30'),
('C0002','Customer2', '2017-11-08 21:21:30')
INSERT INTO [dbo].[Machine]
([Code]
,[Name]
,[Condition]
,[LastModified])
VALUES
('M0001','Machine1', 'Perfect', '2017-11-08 21:21:30'),
('M0002','Machine2', 'Good', '2017-11-08 21:21:30')
Publish the project to the Azure tenant to provision the Azure SQL DB.
3. Create the target DW project

Create the target DW project and add the scripts for schema, staging tables, dimension tables and fact tables:
Schema – prod:
CREATE SCHEMA [prod]
Schema – stg:
CREATE SCHEMA [stg]
Staging – Customer:
CREATE TABLE [stg].[Customer]
(
[Code] int NOT NULL,
[Name] VARCHAR(50) NOT NULL,
[LastModified] DATETIME2 NOT NULL
)
Staging – Machine:
CREATE TABLE [stg].[Machine]
(
[Code] int NOT NULL,
[Name] VARCHAR(50) NOT NULL,
[Condition] VARCHAR(10) NOT NULL,
[LastModified] DATETIME2 NOT NULL
)
Staging – MachineCycle:
CREATE TABLE [stg].[MachineCycle]
(
[CycleId] int NOT NULL,
[MachineName] varchar(50) NOT NULL,
[CustomerName] varchar(50) NOT NULL,
[StartDateTime] datetime2 NOT NULL,
[EndDateTime] datetime2 NOT NULL,
[LastModified] DATETIME2 NOT NULL
)
Dimension – DimCustomer
CREATE TABLE [prod].[DimCustomer]
(
[Id] int NOT NULL PRIMARY KEY IDENTITY,
[Code] int NOT NULL PRIMARY KEY,
[Name] VARCHAR(50) NOT NULL,
[CurrentRow] bit NOT NULL,
[ValidTo] DATETIME2 NULL,
[LastModified] DATETIME2 NOT NULL
)
Dimension – DimMachine
CREATE TABLE [prod].[DimMachine]
(
[Id] int NOT NULL PRIMARY KEY IDENTITY,
[Code] int NOT NULL PRIMARY KEY,
[Name] VARCHAR(50) NOT NULL,
[Condition] VARCHAR(10) NOT NULL,
[CurrentRow] bit NOT NULL,
[ValidTo] DATETIME2 NULL,
[LastModified] DATETIME2 NOT NULL
)
Facts – FactMachineCycle
CREATE TABLE [prod].[FactMachineCycle]
(
[CycleId] int NOT NULL PRIMARY KEY,
[MachineId] int NOT NULL,
[CustomerId] int NOT NULL,
[DateKey] int NOT NULL,
[Duration] float NOT NULL,
[RowAdded] DATETIME2 NOT NULL
)
In addition to the tables above we also need a Date Dimension table and the scripts to generate the table. There are plenty of scripts you can find from Google, e.g., https://www.codeproject.com/Articles/647950/Create-and-Populate-Date-Dimension-for-Data-Wareho. The generated DimDate table should look like:

Finally, we need to publish the project to Azure and will get the DB deployed.

4. Create Azure Data Lake directory
Create a directory in Azure Data Lake, e.g., “ADFDW”, and organise the sub-directory hierarchy as year -> month -> day.

The sample csv data includes the columns of cycleID, CustomerCode, MachineCode, StartDateTime, EndDateTime, and EventTime.

Now we have done our preparation work, the next blog post will cover the steps to build ADF pipelines for dimensional tables ETL.












You must be logged in to post a comment.