
After logical plans are optimised by the Catalyst Optimizer rules, SparkPlanner takes an optimized logical plan and converts it into one or more candidate physical plans. The best physical plan is expected to be selected based on a cost model approach, i.e. comparing the CPU and IO costs of the candidate physical plans and selecting the least costly physical plan (*Until Spark 3.0.0, the cost model has not been implemented, instead, the first of the candidate physical plans is returned).
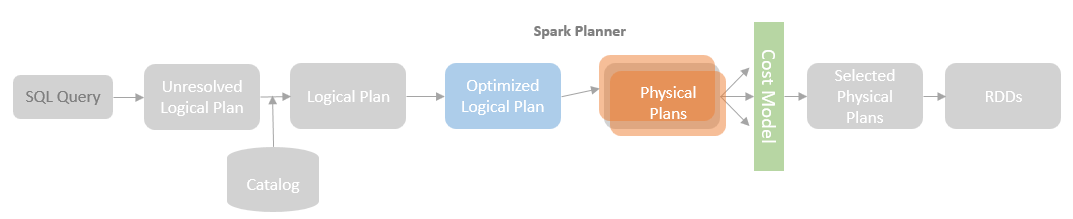
SparkPlanner
SparkPlanner is a concrete implementation of the SparkStrategies abstract class, which implements the platform-independent Catalyst QueryPlanner class. The QueryPlanner class is the root class of all the implementations that transform a logical plan into a physical plan. The QueryPlanner class is platform-independent and is located in the “catalyst” package instead of the Spark SQL “execution” package. This enables the QueryPlanner to be implemented at any platform instead of Spark dependent.

The QueryPlanner class defines a strategies variable, which is expected to be overridden by the child classes that specify a list of Strategy objects of the GenericStrategy type. The plan method in the QueryPlanner class applies the list of specified strategies to generate one or more physical plans.
The SparkStrategies class is the Spark implementation of the QueryPlanner class, which encapsulates a list of strategy implementations with Spark. The SparkStrategies class is still an abstract class. The SparkPlanner is the concrete implementation of the QueryPlanner. As mentioned in the previous blog post, the QueryExecution instance of the current query calls the plan method of the SparkPlanner instance (which is associated with the SessionState of the current SparkSession) to run through the specified strategies to transform a LogicalPlan into an Iterator of SparkPlans.
SparkPlan
Same as the LogicalPlan class, the SparkPlan class is also a child of the root TreeNode class. That means that SparkPlan is also a recursive data structure that contains a tree of sub SparkPlan nodes representing physical operators.

Spark SQL provides a rich set of physical operators, each of which is encapsulated in a concrete child class of the SparkPlan class. Those classes can be categorised based on the number of their child nodes.

- LeafExecNode – The physical execution nodes of the LeafExecNode type (i.e. the child of the LeafExecNode class) have no child node. Most of data source related nodes belong to this type, such as DataSourceScanExec, LocalTableScanExec, and RDDScanExec.
- UnaryExecNode – The physical execution nodes of the UnaryExecNode type have one single child node. Most of transformation related nodes belong to this type, such as FilterExec, SortExec, and ExpendExec.
- BinaryExecNode – The physical execution nodes of the BinaryExecNode type have two child nodes. The phyical operators requiring two children, such as Join, belong to this type.
- Others – Apart from the three types of nodes mentioned above, there are some utility nodes which do not fall into any of those types, but instead those nodes directly inherit from teh SparkPlan node, such as CodegenSupport, DummySparkPlan, and MyPlan.
LogicalPlan to SparkPlan Mapping
Spark strategies transform LogicalPlan to SparkPlan, in either a one-to-one mapping way or a pattern matching mapping way.
For the one-to-one mapping, a LogicalPlan node is mapping to a corresponding SparkPlan, such as the “Sort” logical plan is mapping to the “SortExec” spark plan.

The Spark strategies using the one-to-one mapping transformation, such as the “BasicOperators” strategy, simply returns the corresponding spark plan operator for a logic plan operator.

For the pattern matching mapping, if a predefined pattern consisting of one or more logical plan operators is found by a strategy, the strategy will transform the portion of the logical plan as a whole to the corresponding spark plan portion, which might consist of multiple spark plan operators.

Here is an example of this kind of pattern pre-defined by Spark, “ExtractFiltersAndInnerJoins”.

Planning Strategies
Different planning strategies are defined in a strategy class for a logical operator. For example, the “Aggregation” strategy class defines the strategies to plan aggregation with non-distinct aggregation expressions and aggregation with distinct aggregation expression.
Taking the following query as an example that does not contain distinct aggregation:


The “Aggregate” logical operator is transformed by the “Aggregation” strategy into two “HashAggregate” physical operators, one “partial” aggregation (aggregating in the original executors) and one “final” aggregation (aggregating after the shuffle).
(* the “Exchange” (Shuffle) operator is not added by the “Aggregation” strategy, but instead, it is added by the “EnsureRequirement” rule at the query execution preparations stage.)

For a query containing distinct aggregation expressions, such as:


“Aggregation” strategy applies a different implementation that transforms the logical “Aggregate” operator into four physical “HashAggregate” operators.

This blog post gives an overview of how SparkPlanner works. I will cover the details of some important strategies in the following blog posts.
