
After two lengthy blog posts on Catalyst Optimizer rules, this blog post will close this topic and cover all the remaining rules.
Batch – Operator Optimization (continue)
Continue with the “Operator Optimization” batch:
CollapseRepartition
The CollapseRepartition rule combines adjacent repartition operators. As we know, the repartition function and the coalesce function can be used for changing the number of partitions of a dataset. The repartition function can be used to increase or decrease the partitions, which enable the shuffle, and the coalesce function can only be used to decrease the number of partitions, which do not enable the shuffle.
When a non-shuffle Repartition (coalesce) operator has a child of shuffle Repartition operator, returns the child if the numPartitions of the parent is bigger.



If the numPartitions of the shuffle Repartition is bigger, keep both Repartition operators unchanged.



When a RepartitionByExpression operator has a child of Repartition or RepartitionByExpression, remove the child.


CollapseProject
The collapseProject rule combines two Project operators. As the example shows below, the two Project operators are merged into one.



Combine Operators
Considering the following rules work in a similar way, I will explain them together.
- CombineFilters
- CombineLimits
- CombineUnions
Those combine operators rules combine two adjacent operators into one by merging the operator conditions.
The CombineFilters rule combines two adjacent filters into one by merging the filter conditions of the two filter operators using AND logic.
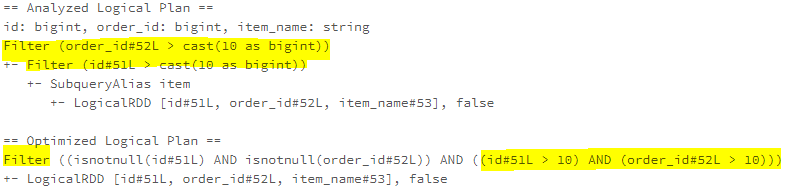
The CombineLimits rule combines two adjacent Limit operators and uses the smaller limit value.



The CombineUnions rule combines all the Union operators.



Constant Evaluation
The following rules are mainly used to process constants, so I group them together:
- NullPropagation
- ConstantPropagation
- OptimizeIn
- ConstantFolding
- ReorderAssociativeOperator
- ReplaceNullWithFalseInPredicate
- CombineConcats
The NullPropagation rule evaluates the Null literal with equivalent literal value depending on the data type.



The ConstantPropagation rule substitutes an attribute with the value which can be evaluated in the conjunctive expression. Taking the following query as an example, the ‘id’ attribute in the second part of the filter condition, order_id = 100 + id, can be substituted with the ‘id’ value in the first part.



The OptimizeIn rule is used for optimising the IN predicates. When there are literal repetitions in the IN values list, the repetitions are removed.



In addition, if the size of the IN values list is larger than the predefined threshold, the IN operator is replaced with the INSET operator which is much faster.




The ConstantFolding rule evaluates the expressions and replaces them with equivalent Literal values.



The RecorderAssociativeOperator rule first reorders the associative integral-type operators and then fold all constants into one.



The null value is evaluated as false in a predicate. The ReplaceNullWithFalseInPredicate rule replaces null value with false.



The CombineConcats rule combines the nested concat expressions.

Operator Simplication
The following rules are mainly used for simplifying operators:
- LikeSimplification
- BooleanSimplification
- SimplifyConditionals
- SimplifyBinaryComparison
- PruneFilters
- SimplifyCasts
- SimplifyCaseConversionExpressions
- RewriteCorrelatedScalarSubquery
- EliminateSerialization
- RemoveRedundantAliases
- SimplifyExtractValueOps
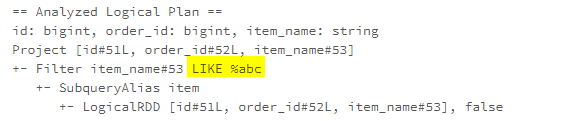
LIKE expressions can be used to match a string a full regular expression in a predicate. When the patterns to match do not need full regular expressions, such as ‘%abc’ (for startsWith condition) or ‘abc%’ (for endsWith condition), The LikeSimplification rule can replace the Like expressions with the faster StartsWith or EndsWith expressions.


The BooleanSimplification rule simplifies the boolean expressions in a predicate. When a predicate consists of multiple boolean expression parts, if an expression part can be determined without evaluating the other parts, the predicate can be simplified.



When a filter condition consists of constants and can be determined at the optimisation stage, the SimplifyConditionals remove the condition and return the result (determined by the condition) directly.



When the result of a binary comparison can be determined at the optimisation stage, the SimplifyBinaryComparison rule replaces the binary comparison expressions with the semantically-equal, true or false expressions



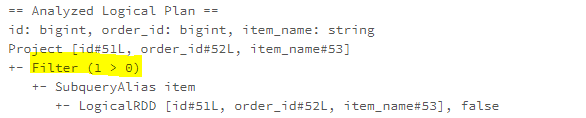
The PruneFilters rule removes the filters that can be evaluated trivially.


The SimplifyCasts rule removes the unnecessary Cast expressions when the data type of the value to cast is same with the expected data type.



The SimplifyCaseConversionExpressions rule removes the case conversion expressions when those expressions can be evaluated and resolved at the optimisation stage.



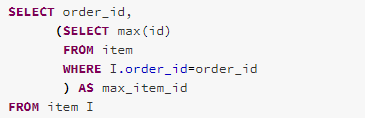
The RewriteCorrelatedScalarSubquery rule rewrites correlated ScalarSubquery expressions into LEFT OUTER joins.

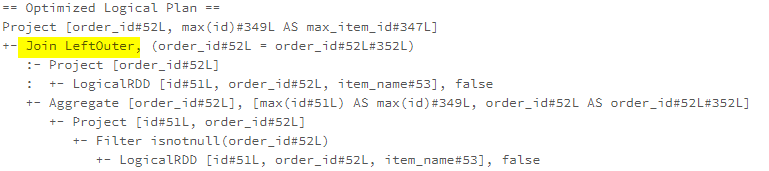
The optimised query can be represented in the following way.

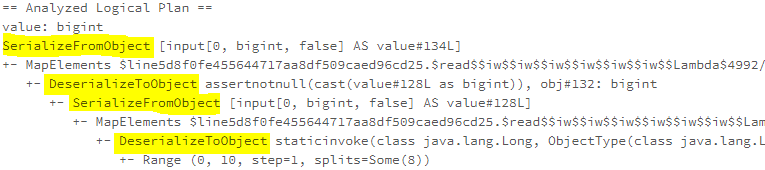
The EliminateSerialization Rules eliminate unnecessary serialisation or deserialisation operations. For example, the back to back map operations in the following query will have a SerializeFromObject operator immediately under a DesericalizeToObject operator. As there is no need for data exchange between nodes between the first map operation and the second map operation, the serialisation/deserialisation operation in between is not necessary and can be removed.

When an alias does not change the name or metadata of a column, this alias is redundant and useless for the query. The removeRedundantAliases rule removes the redundant alias from the logical plan.



The SimplifyExtractValueOps rule removes unnecessary data struct creation when the value(s) required for the query can be directly extracted.
“Array” example:
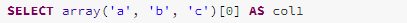
“Map” example



“Named_Struct” example


Batch – Early Filter and Projection Push-Down
This batch is a placeholder for the rules that push filters and projections into scan nodes.
Batch – Join Reorder
This batch includes the CostBasedJoinReorder rule, which is a cost-based Optimizer rule for finding the most efficient join orders based on the statistics of the relations involved in the joins.
The fundamental idea behind the Cost Model in Spark SQL is to compute the costs of all the candidate physical plans generated by the Spark Planner and then select the least expensive one. However, until Spark 3.0.0, the Cost Model has not be implemented yet. Instead, the CostBasedJoinReorder rule is applied at the logical plan optimisation stage. To enable this rule, the spark.sql.cbo.enabled flag and the spark.sql.cbo.joinReorder.enabled flag need to be set as true.
The CostBasedJoinReorder rule collects statistics of the relations involved in the joins, computes the costs of all the valid join combinations and finds the best join combination using a predefined cost formula.

Batch – Eliminate Sorts
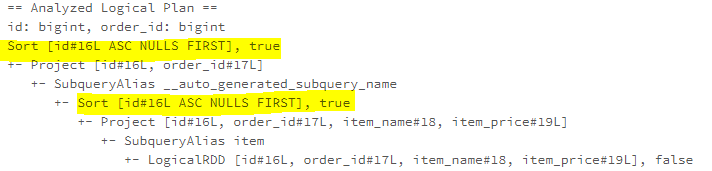
This batch includes the EliminateSorts rule, which removes the necessary Sort operators.


Batch – Decimal Optimizations
This batch is used for optimising Decimal calculations. For Spark 3.0.0, one rule, DecimalAggregates, is included in this batch. The DecimalAggregates rule, if possible, internally converts a Decimal to an unscaled Long value. The use of an unscaled Long value of Decimal is expected to speed the aggregation calculations.



Batch – Object Expressions Optimization
This batch includes Optimizer rules related to object manipulation for the Dataset API, including:
- EliminateMapObjects – eliminate MapObjects operators if types for input and output are primitive types with non-nullable and no custom collection class specified representation of data item
- CombineTypedFilters – combines two ajdacent TypedFilters into one
- ObjectSerializerPruning – prunes unnecessry object serializers
- ReassignLambdaVariableID – reassign per-query unique ID to LambdaVriables so that the codegen cache can be hit more often
Batch – LocalRelation
The “LocalRelation” batch will be executed twice, the first execution is before the execution of major Optimizer rules and the second execution is after. The first batch execution has been explained in the previous blog post, which focuses on simplifying the logical plan for avoiding potential heavy optimizer rules. This is the second batch execution, which collapses logical plans consisting of empty local relations. The empty local relations are generated by the PruneFilters rule in the “Operator Optimization” batch. Therefore, this batch execution needs to happen after the “Operator Optimization” batch.
Batch – Check Cartesian Products
This batch includes the CheckCartesianProducts rule which checks whether or not a join operation is a cartesian product. When the CROSS_JOIN_ENABLED flag is set as false, throw an error if the join is a cartesian product.
Batch – RewriteSubquery
This batch includes the following Optimizer rules, which are also included in the “Operator Optimization” batch executed earlier.
- RewritePredicateSubquery
- ColumnPruning
- CollapseProject
- RemoveNoopOperators
Another run of those rules can optimise the operators generated after the “Operator Optimization” batch execution.
Batch – NormalizeFloatingNumbers
This batch includes the NormalizeFloatingNumbers rule, which handles special floating numbers (e.g. NaN and 0.0/-0.0). different NaNs need to be treated as same, and ‘0.0’ and ‘-0.0’ need to be treated as same, in the cases, including values comparison, aggregate grouping keys, join keys, and window partition keys.
