
In this blog posts, I will dig into the execution internals of the runnable commands, which inherit from the RunnableCommand parent class. The runnable commands are normally the commands for interacting with the Spark session catalog and managing the metadata. Unlike the data query alike operations which are distributed and lazily executed in Spark, the runnable commands execute eagerly in the driver only. Before looking into the execution details of the runnable commands, I will first give an example to demonstrate a typical execution flow of the runnable commands at a high level.
The Journey of a Runnable Command
Here I use one of the simplest runnable commands, CreateDatabaseCommand, to walk through its execution flow.

From the query plan of the example query, we can see that a logical operator, CreateDatabaseCommand, is generated and used at the analysis and optimisation stages. In the physical plan of the query, we can see the CreateDatabaseCommand is passed as a parameter of an “Execute” node.

Internally, the “Execute” node represents the ExecutedCommandExec physical operator, which triggers the run method of the children of the RunnableCommand class. The concrete database creation logic is implemented in the overridden run method in the CreateDatabaseCommand command, which encapsulates the metadata of the database parsed from the query into a CatalogDatabase object and then call the createDatabase method of the HiveSessionCatalog instance of the current Spark session. The HiveSessionCatalog then calls the createDatabase method of the HiveExternalCatalog instance, which relays the call to the HiveClientImpl instance. The HiveClientImpl instance then talks to Hive metastore set up which is used as the external catalog for the current spark session. The CatalogDatabase object which holds the metadata of the database to create is converted to a Hive-supported HiveDatabase object and is passed to Hive. Internally, Hive calls the createDatabase method of the MetaStoreClient instance in Hive to write the database metadata into the Hive metastore database.

In the following sections, I will look into the details of the components involved in the command journey.
RunnableCommand & ExecutedCommandExec
The RunnableCommand is the parent class of all the runnable commands for metadata-based operations, such as creating DB objects, altering schemas, profiling the tables and collecting statistics. I have created the following chart to include all the runnable commands in the org.apache.spark.sql.execution.command package.

The RunnableCommand is a generic logical command that defines an abstract run method, which needs to be overridden by the concrete implementation of the child commands.

The RunnableCommand is a logical plan which is not executable. The physical execution of the runnable commands is run by the ExecutedCommandExec physical operator. A lazy field, sideEffectResult, is defined in the ExecutedCommandExec, which wraps up any side effects caused by the run method execution of the command. The sideEffectResult variable is referenced in the doExecute method so that the command run method can be executed eagerly.

SessionCatalog
As runnable commands are normally responsible for metadata-based operations, the main interface for them to interact with the underlying metadata store is the SessionCatalog. A SessionCatalog instance holds the reference to ExternalCatalog, the abstract of the underlying metadata store. For Spark 3.0.0, two implementations of the ExternalCatalog are supported: the InMemoryCatalog for development or test purpose, and the HiveExternalCatalog for production deployment.
Apart from the ExternalCatalog holding the database objects metadata, SessionCatalog is also the place to hold other types of metadata, such as:
- GloabalTempViewManager – SessionCatalog holds an instance of the GlobalTempViewManager, which registers the temporary views for sharing among all Spark sessions and keep alive until the Spark application terminate.
- TempView – SessionCatalog creates a mutable HashMap for registering the temporary views which is alive within the current Spark session. The name of the view is stored as the key and the logical plan of the view is stored as the value in the temp view HashMap.
- FunctionRegistry – the catalog for the metadata of the user defined functions, which is used for looking up UDFs by an Catalyst Analyzer.
- SQLConf – enables the access of the configurations of the Spark session.
- tableRelationCache – cache of logical plans

HiveSessionCatalog
The Hive support has to be enabled by calling the enableHiveSupport method when building a SparkSession in order to use HiveExternalCatalog. If the Hive classes are found in the current Spark deployment, the CATALOG_IMPLEMENTATION.key is set to “hive”.

SparkSession uses the CATALOG_IMPLEMENTATION setting to choose the corresponding session state builder for building the SessionCatalog implementations. When the hive support is enabled, a HiveSessionCatalog instance is created for the current SparkSession. This HiveSessionCatalog instance creates an instance of the HiveExternalCatalog, the Hive implementation of ExternalCatalog, which contains the interface for interacting with the underlying Hive metastore.


Internally, the HiveExternalCatalog communicates with Hive through the HiveClientImpl. The backend metastore database will be updated to reflect the metadata related commands.
Hive Metastore Database
To understand the metadata operations supported by the Hive Metastore, it would be helpful to understand how the metadata is stored in the Metastore. Hive Metastore uses a relational database to store the metadata. You can find the database creation scripts for a number of supported database providers from the Hive Github Repo.

Those metastore database creation scripts enable us to look into the schema of tables for storing metadata for different database objects, such as table, partition, function and so on.
Here is a simplified chart, depicting the main tables using in a metastore database.

Here is a brief description of the main tables:
- DBS – stores the metadata of databases, such as database id, description, location, owner. The associated DATABASE_PARAMS table stores the database parameters in key-value pairs.
- FUNC – stores the metadata of user-defined functions.
- TBLS – stores the metadata of tables. The associated TABLE_PARAMS table stores table parameters. The associated TAB_COL_STATS stores statistics of table columns.
- PARTITIONS – stores partition information of a table. The PARTITION_KEYS table stores the partition keys of the table, such as ‘Location’. The PARTITION_KEY_VALS table stores the value of the key of a partition, such as ‘London’ for the ‘Location’ key. The PART_COL_STATS table stores column statistics of a partition.
- SDS – stores source data file information, such as input_format, is_compressed, location, output_format etc.
- COLUMNS_V2 – stores metadata of columns, such as column types and sort codes.
- SERDES – stores serialisation information, including the qualified serialisation class name.
Catalog Domain Objects
Spark SQL defines a collection of internal Catalog domain objects, which are used for transferring metadata between the components involved in the command execution flow. The Catalog domain objects defined in Spark SQL will be converted to their corresponding Hive-supported domain objects before sending them to Hive.
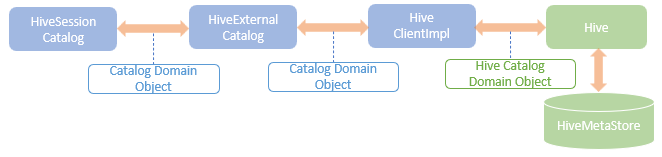
The Catalog domain objects covers a wide range of catalog objects, such as database, table, column, statistics, storage format, function, etc.

The snapshot below shows the attributes of the CatalogTable.


