
This blog post discusses another main component in the Spark Structured Streaming framework, Sink. As the KafkaSink will be covered when discussing the Spark-Kafka integration, this blog post will focus on ForeachBatchSink, ForeachWriteTable, FileStreamSink and DeltaSink.

Spark Structured Streaming defines the Sink trait representing the interface for external storage systems which can collect the results of a streaming query. There is only one method defined by Sink trait, ‘addBatch‘ which takes the ‘batchId‘ and the DataFrame representing the batch data as arguments. All the concrete Sink classes need to implement this method for adding a batch of output data from a streaming query to the external data storage. The ‘batchId‘ can be used to preserve exactly once semantics, such as what the FileStreamSink does. That requires the data for a given ‘batchId‘ is deterministic, which means the same batch of data will be processed by the ‘addBatch’ method, overwritten or ignored, if the ‘batchId‘ passed to the method is same. Therefore, the retry operations from a failure discovery won’t write duplicated data to the sinks.

Spark provides a number of built-in Sink implementations for different output storage systems, including the core ones for being used in the Production environment, such as the FileStreamSink for outputting the streaming results to the Hadoop-computable storages in a variety of supported file formats, the KafkaSink for outputting the streaming results to the downstream streaming systems, and the DeltaSink for outputting the streaming results to Delta table formats. However, the most flexible built-in Sinks are the ForeachBatchSink and ForeachWriteTable which allow the end-user developers to inject their own data writing implementations for arbitrary output storage systems.
ForeachBatchSink
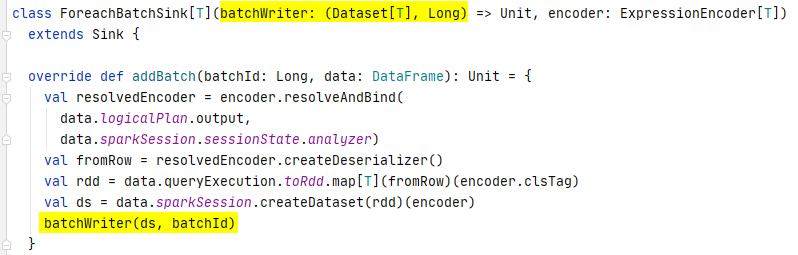
ForeachBatchSink allows end-user developers to specify a custom writer function that is executed to write the output data of every micro- batch of a streaming query to the target storage system. The implementation of the ForeachBatchSink is simple. The DataStreamWriter provides the foreachBatch method for end-developers to register their own writer function. The dataframe representing the micro-batch data and the batchId are passed into the writer function.

When the streaming query is being initialised, the ForeachBatchSink instance is created using the specified custom function as the writer.

ForeachWriteTable & ForeachWriter
ForeachWriteTable supports custom writing logic on the data output of a streaming query as well. Compared to the ForeachBatchSink which processes data in micro-batch as a whole, the ForeachWriteTable allows custom writing logic on each row.
For the end-user developers, they can define the custom writing logic in a sub-class which implements the abstract ForeachWriter class.

The custom writing logic defined in the sub-class will be executed for each task on executors, therefore, an instance of the sub-class will be initialised by each partition. Three methods in the base ForeachWriter class need to be implemented in the sub-class:
- open – open connection for writing the current partition of data in the executor.
- process – when the ‘open’ method returns ‘true’, write a row to the connection.
- close – close the connection.
After the end-user developer defined the sub-class, they can be applied by calling the foreach method in the DataStreamWriter. Internally, the sub-class is applied in the following steps:
- DataStreamWriter sets the output of the streaming query to be processed using the custom writer object.
- When the start method of the DataStreamWriter is called, a ForeachWriteTable instance is created using the custom writer object as the writer of the sink.
- MicroBatchExecution creates the foreach StreamingWrite using the write builder of the ForeachWriteTable.
- The WriteToMicroBatchDataSource node is created with the foreach StreamingWrite as the write and added to the logic plan. There is no physical plan corresponding to the logical plan node, instead it will be converted to WriteToDataSourceV2 before execution.
- The WriteToDataSourceV2Exec physical plan node is planned for the WriteToDataSourceV2 logical plan node.
- When the physical plan is being executed, the ForeachWriterFactory is initialised by the foreach StreamingWrite. The DataWritingSparkTask running on executors create the ForeachDataWriter instance and call the write method to write each InternalRow in the current partition.
- The write method of the ForeachDataWriter finally executes the custom writing logic defined in the custom ForeachWriter class.

FileSystemSink
FileSystemSink writes the results of a streaming query to parquet files in a target hadoop-compatible storage system. Each micro-batch is written out to a unique directory by the FileFormatWriter. The FileSystemSink maintains an instance of the FileStreamSinkLog which records the list of the successfully writing files in a batch.

When the addBatch method of the FileStreamSink is called, it first fetches the id of the latest committed batch and compares to the id of the current batch. If the latest batch id is larger or equal to the current batch id, it means the current batch has been committed before, so the current batch needs to be skipped to avoid duplications in sink.
The committer used by the FileFormatWriter is an instance of ManifestFileCommitProtocal which is capable to track the list of files written or being to write in the FileStreamSinkLog. The committer intialises an ArrayBuffer, pendingCommitFiles, when setting up the spark job on driver. When the job is being executed, the setupTask and commitTask are executed to write the files and to log the commited file info (SinkFileStatus) in the pendingCommitFiles. When all the tasks complete successfully, the SinkFileStatus of all the files in the pendingCommitFiles along with the current batch id are added to the FileStreamSinkLog.
DeltaSink
Strictly speaking, DeltaSink is not a built-in sink in Spark Structured Streaming, but instead it is offered by the delta lake package which supports to write the results of streaming query into a Delta table. Thanks to the transaction log, Delta table natively supports atomic table write transaction, i.e. a successful full commit or no write. The transaction log keeps a track of all the atomic write transactions that have been done to the target delta table. DeltaLog is the class representing the transaction log in Detla lake, which can be used to query or to modify the log by adding new atomic collections of actions. All read and modification actions need to be conducted through the OptimisticTransaction, which is used by the DeltaSink to conduct the set transaction, write files and remove files actions.
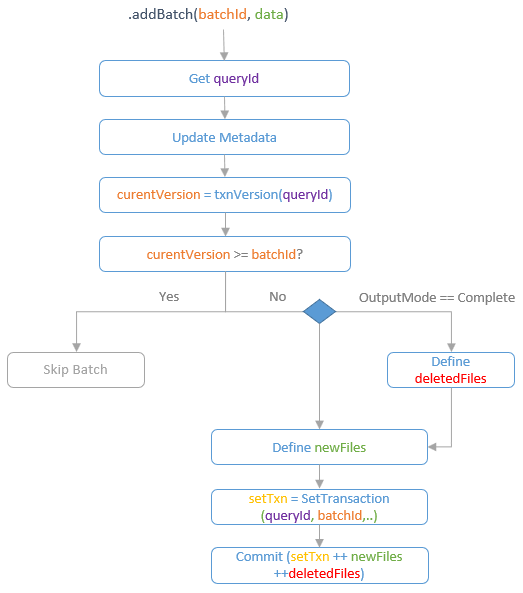
When DeltaSink is trying to write a batch to Delta table through the addBatch method, to achieve the exactly-once semantics, the id of the latest version that has committed for the current stream query is looked up through the txnVersion method of the OptimisticTransaction. The id of the latest version is actually the batchId of the last batch. Therefore, we can know whether the current batch has been committed or not through comparing the current batchId and the latest version id. If the current batch has been committed before, skip the current batch write. If no, prepare the file write actions for committing.
DeltaSink supports the Append and the Complete output modes. If the output mode of current batch write is ‘Complete’, define the action for removing the existing files so that the ‘Complete’ output mode can be achieved through ‘truncate + append’. Then call the writeFiles method of the transaction to define the write action of the batch data into new data files. Apart from the file write/remove actions, the SetTransaction action is also required to set the transaction version id as the current batchId so that it can be used to prevent the same batch to be committed again. Finally, the commit method of the transaction is called to commit the actions defined above.
