
This blog post discusses another stateful operation supported by Spark Structured Streaming, Stream-Stream Join, which joins two streaming datasets. Unlike static datasets join, for the rows reaching to one side of the input streams in a micro-batch, the matching rows would highly likely be not received in the other side of the input streams at that point of time, but instead, the matching rows will reach to the other side at a time in future. Therefore, the rows from the input streams need to be buffered for joining with the future rows from the other side input stream. In this blog post, I will explore how Stream-Stream Join works under the hood.
Firstly, let’s take a look at a stream-stream join query example and its execution plan. This example uses an “Inner” join type query. Up to Spark v3.3, Spark Structured Streaming supports Inner, Outer (left, right, and full), and Left Semi. In the blog post, I will first discuss the stream-stream join using Inner join type as example and then highlight the differences of how Outer and Left Semi work.

In this example, we have two input streams. Each of them has a randomly generated join key, an integer ranging from 1 to 10. In addition, there is a generated value column for each input stream that randomly generates an integer. Watermarks are set for both input streams, the left side is set to 1 hour and the right side is set to 2 hours. The two streams are joined on the generated join keys. Two additional filters are defined to filter on the value columns of both side streams.
This is the physical plan generated for the query above. From the plan, we can see that the join is conducted by the StreamingSymmetricHashJoin (StreamingSymmetricHashJoinExec) operator. For each join side of the operator, an EventTimeWatermark operator is added to the plan for defining the watermark filtering. The value filter is pushed down from the join condition (at the optimisation phase). Before the StreamingSymmetricHashJoin operator is executed, the partitions are reshuffled to HashClusteredDistribution so that the rows with the same join keys from the two input streams are placed in the same executors.

When the StreamingSymmetricHashJoinExec operator is being executed, the StateStoreAwareZipPartitionsRDD is created, that zips together the partitions of two child RDDs while sets the preferred location of the pair of hash clustered partitions to the executors where the state stores corresponding to the par of partitions are already loaded. If you want to know more about the locality of state stores, please refer to my previous blog post.
The diagram I draw below depicts the join of the pair of partitions of two input streams in an executor.

Compared to the static datasets join, the stream-stream join, based on StreamingSymmetricHashJoinExec, has two distinct characteristics:
- Use Symmetric Hash Join algorithm
- Join with buffered rows in state store
In the classic hash join, one side of join is made as the Build side and the other side is made as the Probe side. During a joining process, a hash table is created for the build input first, and then the probe input is looped through row by row and each probe side row looks up the matching rows in the build side hash table. In the stream-stream join, as there could be data reaching to either side of the streams at a point of time, it is not possible to fix the build side and the probe side during the stream-stream query execution lifetime. Instead, Spark Structured Streaming performs stream-stream join using symmetric hash join algorithm which handles each join sides with the same process. For each input row on each side, looks up the matching rows in the other side’s state store by the specified key. In other words, either side of the join can behaviour as build side or probe side.
Spark Structured Streaming contains an OneSideHashJoiner class that encapsulates the logics for consuming input rows from one join side and generating join output rows using the other side’s streaming state. For a stream-stream join query, one OneSideHashJoiner instance is created for each input stream.

Each OneSideHashJoiner contains a SymmetricHashJoinStateManager instance, that manages the current join side’s state store and opens up the methods for the OneSideHashJoiner instance to get, append and remove streaming state.
The core method provided by the OneSideHashJoiner is the storeAndJoinWithOtherSide method which executes the actual stream joins. For each streaming micro-batch, the left side’s OneSideHashJoiner first runs this method to process the input rows from the left side stream, and then the right side runs the method to process the input rows from the right side stream.

Within the storeAndJoinWithOtherSide method, the watermark of the input stream is first checked to remove the rows that are older than the specified watermark. The pre join filter, which filters out rows that could not pass the overall join condition, no matter what other side row they are joined with, is then applied to remove the input rows from the subsequent join. For each input row qualified for the join, the join key is extracted from the input row, and the getJoinedRows method of the other side’s SymmetricHashJoinStateManager is called to get matched rows from the other side’s join streaming state store and generate the joined output rows. Next, the processed input row is added to this side’s join state store (depending on the join type). The output row iterators generated from both sides’ OneSideHashJoiners are merged and returned. At the end of the process, i.e., when all the input rows in a micro-batch have been consumed and output generated, the old join state rows which are below the watermark are cleaned up from the state store.
The process described above is based on the Inner Join type. Spark Structured Streaming also supports the Outer Join and the Left Semi Join. For the Outer Joins (Left Outer, Right Outer, and Full Outer), when the join type matches the current side (e.g., left side for Left Outer Join or Full Outer Join), all the input rows from this side joins “null” generic rows.

For Left Semi Join, which only need to join the first matching row from the other side of the join, the excludedRowsAlreadyMatched flag is set to true while calling the getJoinedRows method of the other side’s state store manager so that only one matched row for a join key will be returned for the streaming query.
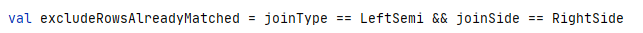

what happens to the state store in case we are not providing timestamp and event-time constraint in inner joins