
In this blog post, I am going to dive into the vectorised Parquet file reading in Spark. Vectorised Parquet file reader is a feature added since Spark 2.0. Instead of reading and decoding a row at a time, the vectorised reader batches multiple rows in a columnar format and processes column by column in batches. The performance test from Databricks shows 9 times faster on column decoding with vectorised Parquet readre compared to the non-vectorised one.

This blog post first introduces the ColumnBatch and ColumnVector that is the basic data structure processed by vectorised Parquet reader. A high-level overview of the vectorised data reading process is then given, followed by a further detailed introduction of the core components that support vectorised Parquet file reading in Spark.
ColumnBatch & ColumnVector
ColumnBatch is the basic unit of data structure that returns by a batch read call to the vectorised Parquet reader. ColumnBatch wraps a list of ColumnVectors, each of which holds the field values of one column in the request dataset result from the batch reading.

The dataset stored in a column batch could be accessed by the potential downstream consumers in a column-based view, i.e. column verctor by column vector, which is the nature format to feed into a vectorised process. However, ColumnBatch also offers a rowIterator public method, which returns the batch dataset in a row-based view with each row is encapsulate in a Spark SQL InternalRow instance.
A ColumnVector instance stores the list of field values of a column in a batch. The element of a column vectore could be accessed by the rowId, which is the batch local 0-based index for values in the ColumnVector.
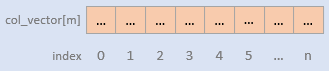
A ColumnVector could be used to store any same type of data. The ColumnVector encapsulates the access methods for each type of data, but only the methods for the current type of data in a ColumnVector instance will be used. The DataType attribute in the ColumnVector instance shows the current data type.
Within a Spark SQL query journey, especially for a large return dataset, a large number of batches might be returned. Instead of creating new ColumnBatch and ColumnVector instances for each batch, Spark SQL vectorised Parquet reader reuses the ColumnBatch and ColumnVector instances during the entire data loading process to minimise the storage footprint. This design, which makes the storage footprint is negligible, allows ColumnVector to be optimised for computing efficiency over storage efficiency.
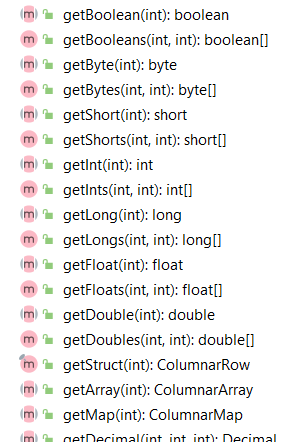
ColumnVector supports both on-heap in-memory storage and off-heap in-memory storage.
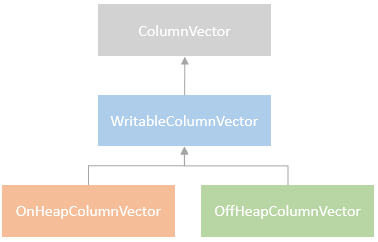
OnHeapColumnVector is the on-heap implementation that is backed by an in-memory JVM array (multiple arrays actually, each of them for each data type, but only is used).

The off-heap version is implemented in the OffHeapColumnVector which stores the column values outside the java heap. Internally, it uses the Unsafe class from the sun.misc package to manage the column vector storage and access. The advantage to using an off-heap version is to avoid the overhead caused by JVM GC, with the costs of extra CPU usage on object serialising and unserialising.
Vectorised Parquet Reading
Spark SQL implements vectorised Parquet reading with three main components, VectorizedParquetRecordReader, VectorizedColumnReader, and VectorizedValuersReader. After a VectorizedParquetRecordReader is initialised and the initBatch method is executed for creating the ColumnBatch instance and the related ColumnVector instances, the parquet file could then be read batch by batch through the nextKeyValue method. For each row group, a new VectorizedColumnReader array with a VectorizedColumnReader instance for each requested column is created. The nextBatch method in the VectorizedParquetRecordReader loops through the array of VectorizedColumnReaders to read the batch data into the respective ColumnVectors column by column. Depending on the data encoding methods, VectorizedColumnReader creates respective VectorizedValuesReader implementation instances to read and decode data. There are two versions of VectorizedValuesReader available at this moment, VectorizedRleValuesReader (for RLE/Bit-PackingHybrid) and VectorizedPlainValuesReader (for plain encoding). The Directory decoding logics are encapsulated in the decodeDictionaryIds method of the VectorizedColumnReader. More details will be covered later. The page data reading and decode are done in batch with the specified batch size. The read and decoded column data in a batch will be written into the ColumnVector and returned back to VectorizedParquetRecordReader and then be consumed by the upstream callers with other ColumnVectors in the ColumnBatch.

VectorizedParquetRecordReader
VectorizedParquetRecordReader, an implementation of the abstract RecordReader class, overrides the nextKeyValue method, calling of which starts off the vectorized batch reading. Before the nextKeyValue method could be executed. A VectorizedParquetRecordReader instance needs to be constructed with specified ‘capacity’ (batch size) and memory mode (on-heap or off-heap). The initialize method, inherited from the SpecificParquetRecordReaderBase class, accesses the ParquetMetadata from the footer of the Parquet file, applies the predicate pushdown filter to locate the row groups for reading, and then creates the ParquetFileReader based on the requested schema and located row groups.
The nextKeyValue method calls the resultBatch method to start the batch read flow. If the nextKeyValue method is called for the first time and the ColumnBatch instance has not been created yet, the ColumnBatch instance and ColumnVector instances for all requested columns are created. When the ColumnBatch is ready, nextBatch method is called to read batched column values. One new array of VectorizedColumnreader instances, each of which is used for reading one of the request columns, are created when the nextBatch method is starting to read a new resource group. The nextBatch method loops through the VectorizedColumnReader instances and calls the readBatch method for each VectorizedColumnReader instance.
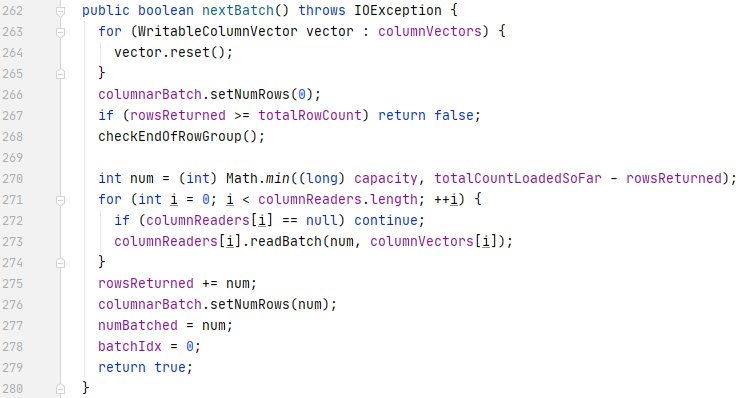
VectorizedColumnReader & VectorizedValuesReader
A VectorizedColumnReader instance is initialised with its respective ColumnDescriptor, which contains the column’s type and schema position information, and the ColumnChunkpageReader for this column, which contains the list of data pages in the column chunk and the dictionary page if the column values are encoded with dictionary encoding.
As mentioned above, for each batch reading, the VectorizedParquetRecordReader loops through all the VetorizedColumnReaders and call the readBatch method of each column reader. At the same time, two parameters are passed in the readBatch method, total (the number of rows to read in this batch), and column (the ColumnVector instance to store the returned column values). When the readBatch method is called for the first time (no column chunk page has been read) or all the rows on the current page have been read, the readPage method is called to initialise the ByteBufferInputStream for reading page data and to create the right types of ValuesReader based on the encoding method of the page.
When a VectorizedColumnReader is being constructed, the dictionary page of the column chunk is read if it exists. a Dictionary instance is initialised from the dictionary page, which will be used for decoding the batch later. The column chunk level flag, isCurrentPageDictionaryEncoded, is also set as true.

When the readBatch method of VectorizedColumnReader is called and the isCurrentPageDictionaryEncoded flag is true, the dictionary encoded column values in the data page will be read into dictionaryIds, a WritableColumnVector instance. The decodeDictionaryIds method of VectorizedColumnReader will then be called to decode the column values in the dictionaryIds by looking up the dictionary read ealier.

If the isCurrentPageDictionaryEncoded flag is false, i.e. the column chunk pages are not dictionary encoded, The read[primitiveType]Batch method will be called to read and decode the column values. A set of read[primitiveType]Batch methods is encapsulated in the VetorizedColumnReader class, each of which is used for reading column values for a primitive data type supported by Parquet. Each method takes three parameters, rowId (starting row id of the batch reading), num (number of rows to read in this batch), and column (the ColumnVector where the returned column values are stored at).
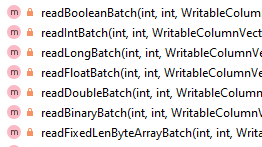
At the time when a page is being read, the initDataReader method of the VectorizedColumnReader is called, which gets the encoding approach from the page header and creates VectorizedValuesReader instance (either VectorizedRleValuesReader or VectorizedPlainValuesReader) accordingly. The read[primitiveType]Batch method will use the VectorizedValueReader instance to decode the column values and put them into the result ColumnVector.
