In my previous blog post, I discussed the requirements and core elements of the rule-based data quality assessments. In this and next blog posts, I am going to walk through the data quality rules designed in the dqops DQ Studio app (one of my R&D initiatives for data quality improvement), ranging from the basic data quality rules for Type 1 (syntactic) data quality issues to the CFD, Machine Learning powered data quality rules for Type 2 (schematic) data quality issues.
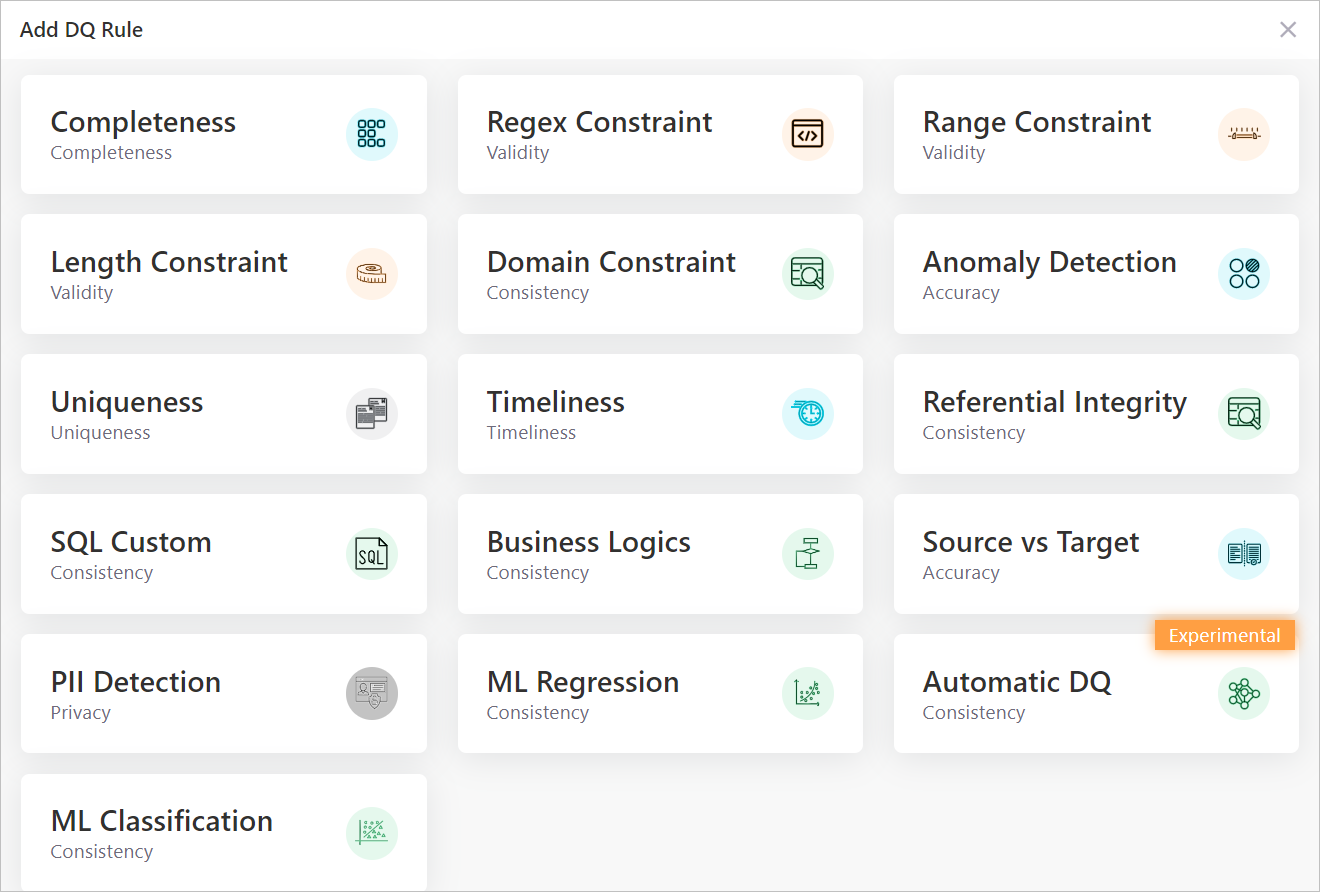
This blog post covers the basic data quality rules for Type 1 data quality issues, including the rules for assessing validity, completeness, accuracy, uniqueness, timeliness and integrity.
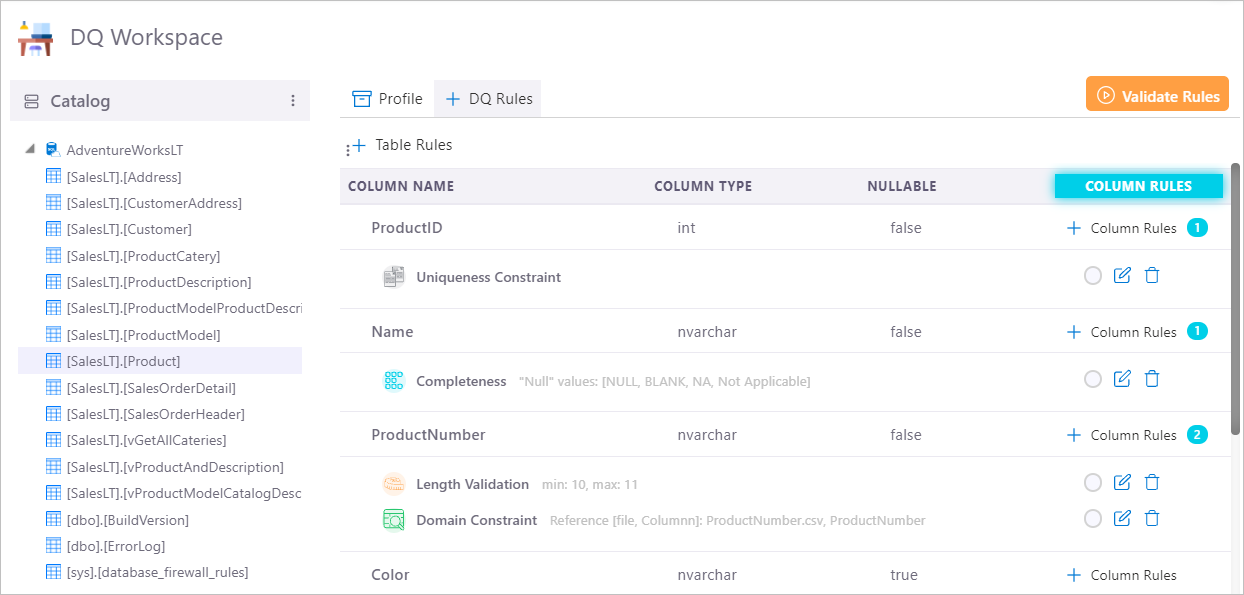
Validity
At the time when this blog post is written, four DQ rule templates have been developed in dqops DQ Studio for assessing the validity of a data field:
- Regex Constraint Rule
- Range Constraint Rule
- Length Constraint Rule
- Domain Constraint Rule
Regex Constraint Rule
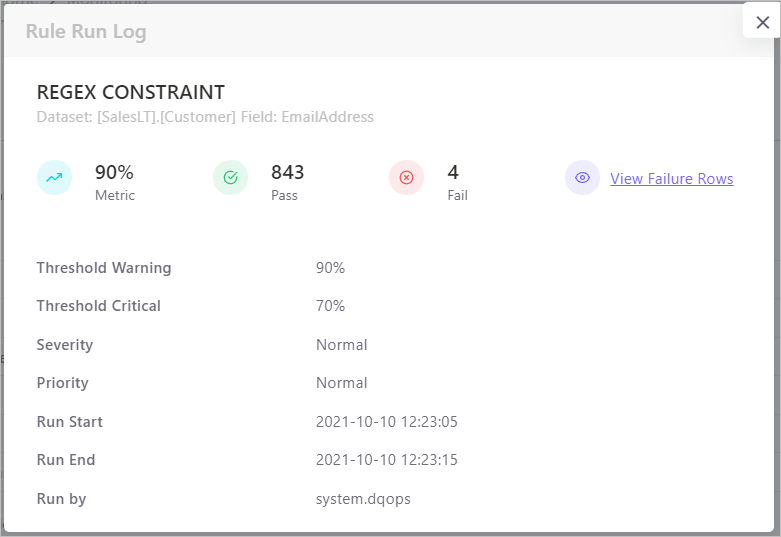
Regex Constraint rule allows the DQ analysts to specify the regular expressions of the valid formats a column has to comply with. This rule scans the column to count the values with the valid formats complying with the specified regular expressions and divide by the count of total rows to calculate the validity metric value.
metric = count({values matching regex}) / total rows

The DQ analysts can select one or more regular expressions from pre-defined, commonly used formats for a column, or define custom regular expressions.

When the rule is being executed, the column associated with this rule is scanned to look up the field values that comply with the specified regular expressions. The result is then logged into a backend database and the rows with invalid values are logged into a low-costs, object-based storage account to keep a full history for the data quality trend analysis and issue investigations.
Range Constraint Rule
Range Constraint rule allows the DQ analysts to specify a valid range of a numerical or date type column. This rule scans the target column to detect the values falling outside of specified range.
metric = 1- count({values out of valid range})/total rows
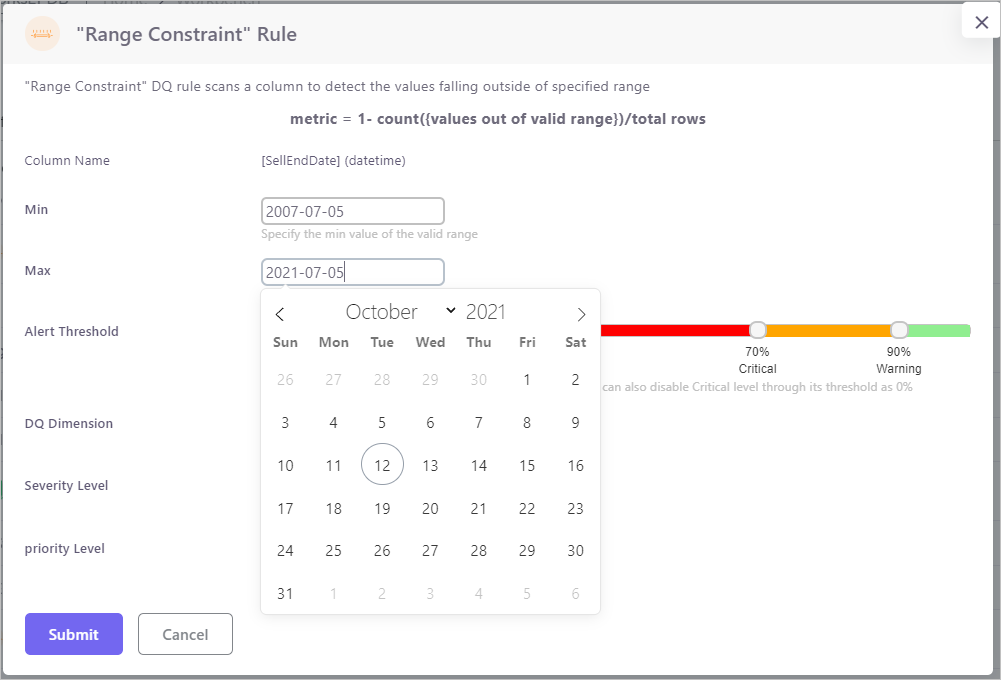
Range Constraint rule detects the data type of the column and generate input controls for DQ analysts to specify the the minimum and maximum numerical values (for numerical column type) or dates (for date column type)
Length Constraint Rule
Similar with the Range Constraint rule, the Length Constraint rule allows DQ analysts to specify the valid length range of a column and detect any field value that falls out of the range, for example, a Length Constraint rule can be used to check the validity of a bank card number column with valid length to be 16 digits.
metric = 1 - count({values out of valid range}) / total rows

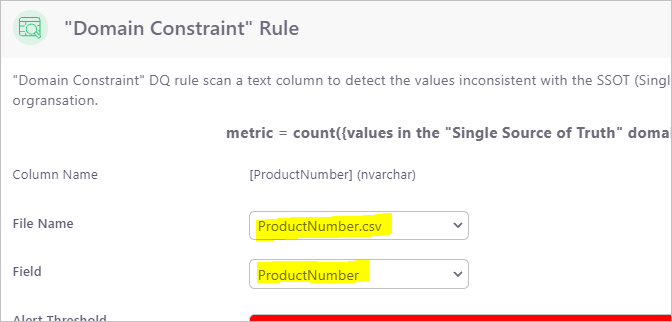
Domain Constraint Rule
Domain Constraint rule allows DQ analysts to pre-define a list of valid domain values or “Golden Records” of an entity attribute, such as “Product Code” and “Cost Center Code”. Any field value that is not on the pre-defined list is invalid.
At the time when this blog post is written, DQ analysts can upload and centerally manage the pre-defined domain values (in csv file format) in the dqops DQ studio.
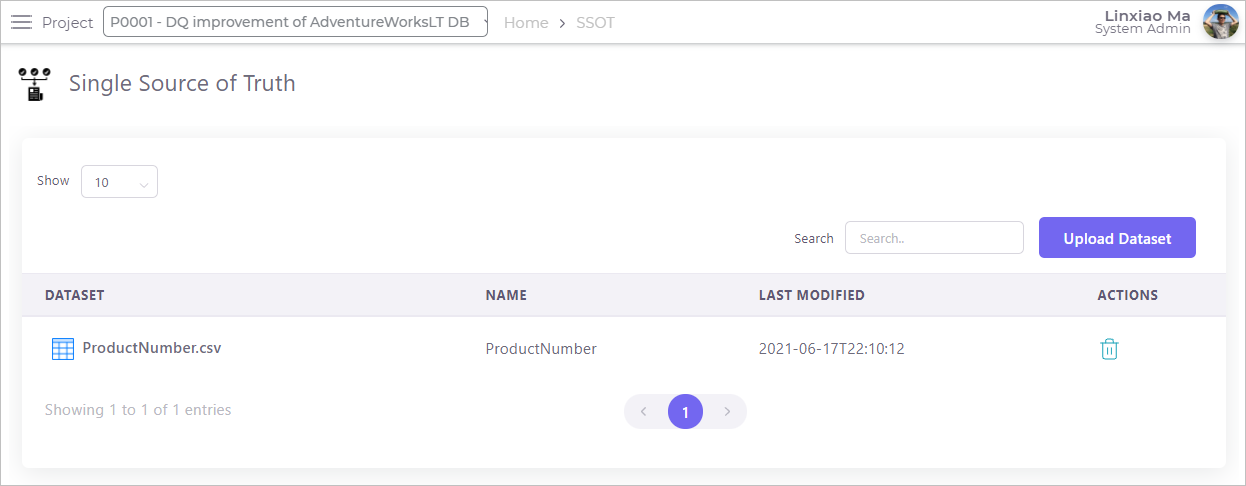
Once the pre-defined domain value csv file is uploaded, DQ analysts can apply the Domain Constraint rule to a column and specify the domain values.
Completeness
Completeness rule scans a column to evaluate the scale of missing values. When the scale of incompleteness of a column reaches to a level, the column can be not usable, especially for LOB datasets with transactional data, missing data implies potential business or IT exceptions or errors.
The missing values refer to not only the syntactic empty or null data type value but also possibly the default values, such as “Not Appliable”, “Default”, 0, 1970-01-01. The default values are either set by client application automatically when a field on the input UI is not filled or users just pick a default value to fill a compulsory form field.
Completeness rule counts the missing values and divide it by the total rows in the dataset and substract the result from 1 to calculate the completeness metric.
metric = 1 - count({missing or default}) / total rows

Accurary
I borrowed the ideas from Apache Griffin for assessing accuracy of a dataset, i.e. comparing the target dataset to a reference dataset that can be treated as reflecting “real world” truth. DQ analysts can create connections to the reference dataset and select columns and aggregate functions to define the comparison rules.
This “Source vs Target” rule can also be used for data reconciliation in a ETL process to validate the target dataset is same with the source dataset.


Uniqueness
Uniqueness rule scan a column to detect the duplicated values.
metrics = count(distinct values) / total rows

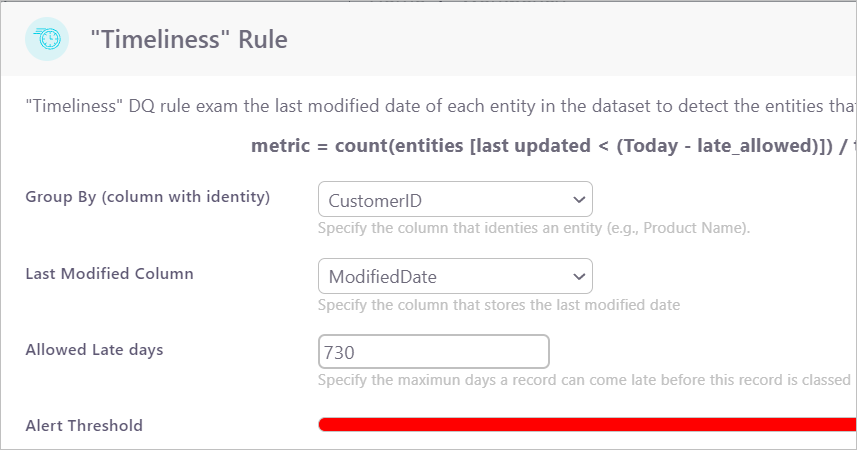
Timeliness
Timeliness rule exams the last modified date of each entity in the dataset to detect the entities that are older than the specified period.
metric = count(entities [last updated < (Today - late_allowed)]) / total entities
Referential Integrity
Referential Integrity rule scan a column to detect the invalid reference values.
metric = 1 - count(invalid values) / total rows

