
The previous blog post introduces a list of basic data quality rules that have been developed for my R&D data quality improvement initiative. Those rules are fundamental and essential for detecting data quality problems. However, those rules have existed since a long, long time ago and they are neither innovative nor exciting. More importantly, those rules are only capable to detect the Type I, “syntax” data quality problems but are not able to find the Type II, “semantic” data quality problems.
Type II “Semantic” Data Quality Problems
Data quality rule is expected to be an effective tool for automating the process of detecting and assessing data quality issues, especially for a large dataset that is labour-intensive to do manually. The basic rules introduced in the previous blog post are effective to detect the Type I problems that require “know what” knowledge of the data, such as the problems falling in the completeness, consistency, uniqueness and validity data quality dimensions.
Type II data quality problems are those “semantic” problems that require “know-how” domain knowledge and experience to detect and solve. This type of problem is more enigmatic. The data looks all fine on the surface and serves well most of the time. However, the damage caused by them to businesses can be much bigger.
Martin Doyle’s 80:20 rule states around 80% of data quality problems are Type I problems and only 20% of data quality problems are Type II problems. However, the Type II problems cost 80% of effort and budget to solve while the Type I problems only takes 20% of effort and budget.
Under the pressure of limited project time and budgets, plus that the type II data quality problems are normally less obvious than the Type I problems, Type II data quality problems are often overlooked and keep unnoticeable until damages are made to the business by the bad data. The later the problems are found, the severe the damages could be. Based on the 1:10:100 rule initially developed by George Labovitz and Yu Sang Chang in 1992, the costs of solving quality problems increase exponentially over time. When it might only cost you $1 to detect and solve data quality problems at the early stage, the costs of failure caused by hidden data quality problems could be $100 or more.
Therefore, it is important to detect and solve Type II problems before they have made damage to the business. Unfortunately, the job of solving Type II data quality problems is not easy that requires domain experts to invest a significant amount of time to study the data, identify patterns and locate the issues. This could become mission impossible when the data volume is getting larger and larger. Not only the current manual approach is expensive and time-consuming but also it is highly dependant on the domain experts’ knowledge and experiences in the business processes, including the “devils in the details” type of knowledge that only exists in those domain experts’ heads.
So, can we find an alternative approach to solve the Type II problems without the dependency on the domain experts’ knowledge and experiences? can we identify the patterns and relations existing in a dataset automatically with the help of the computation power from modern computers to exhaustively scan through all possibilities? The Machine Learning and Data Mining techniques might provide an answer.
Based on my literature review, a number of ML/DM techniques are promising for handling Type II data quality problems. In my dqops R&D project, I have been experimenting with those techniques and exploring the potential ways to adapt them in a software app for non-technical DQ analysts. In the rest of the blog post, I am going to describe the ways I have been exploring in my toy dqops app, focusing on Conditional Functional Dependency and self-service supervised machine learning, with a brief introduction of anomaly detection and PII detection features.
Conditional Functional Dependency (CFD)
CFD, originally discovered by professor Wenfei Fan from the University of Edinburg, is an extension to traditional functional dependencies (FD). FD is a class of constraints where the values of a set of columns X determine the values of another set of columns Y that can be represented as X → Y. CFD extends the FD by incorporating bindings of semantically related values that is capable to express the semantics of data attribute dependencies. CFD is one of the most promising constraints to detect and repair inconsistencies in a dataset. The use of CFD allows to automatically identify context-dependent quality rules. Please refer to my previous blog post for a detailed explanation of CFD
CFD has demonstrated its potentials for commercial adoption in the real world. However, to use it commercially, effective and efficient methods for discovering the CFDs in a dataset are required. Even for a relatively small dataset, the workload to manually identify and validate all the CFDs is overwhelming. Therefore, the CFD discovery process has to be automated. A number of CFD discovery algorithms have been developed since the concept of CFD was introduced. In my dqops app, I have implemented the discovery algorithm from Chiang & Miller in Python. Please refer to the paper on this algorithm from Chiang & Miller for details.
The snapshot below shows the dependencies discovered from Kaggle Adult Income dataset.

Based on the discovered dependencies, DQ analysts can create DQ rules to detect any data row that does not comply with the dependency. In dqops DQ studio, there are two rule templates that can be used to define the dependency constraint, the “Business Logics” rule and the “Custom SQL” rule. The snapshot below shows the definition panel of the “Business Logics” rule.

Self-serivce Supervised Machine Learning
One traditional but effective method for detecting data quality problems is to use “Golden Dataset” as a reference and search for records that conflict with the pattern presented in the “Golden Dataset”. This method is feasible for a “narrow” dataset with a manageable number of columns/attributes. However, for a dataset with a large number of attributes for each record, it becomes impossible to manually identify the patterns in the dataset. Fortunately, this happens to be what Machine Learning is good at.
In my dqops R&D project, I have been exploring the potential approaches to take advantage of Machine Learning techniques to identify Type II data quality problems. There are two prerequisites required for this idea to work:
- A “Golden Dataset”
- A self-service machine learning model builder
The main steps for this idea are:
- DQ analysts prepare the “Golden Dataset”
- DQ analysts train and verify a regression or classification model with the “Golden Dataset”
- DQ analysts apply the trained model to test target datasets
In the dqops app, I have developed a self-service machine learning model builder that allows DQ analysts without machine learning skills to train machine learning models by themselves. Under the hood, the auto-sklearn package is used for the model training.
I have been trying my best to make the self-service model builder as easy to use as possible. DQ analysts just need to upload the “Golden Dataset”, specify the target column (i.e. the dependent variable) and select the task type, regression or classification. Some advanced settings are also enabled for further tunning for advanced users.
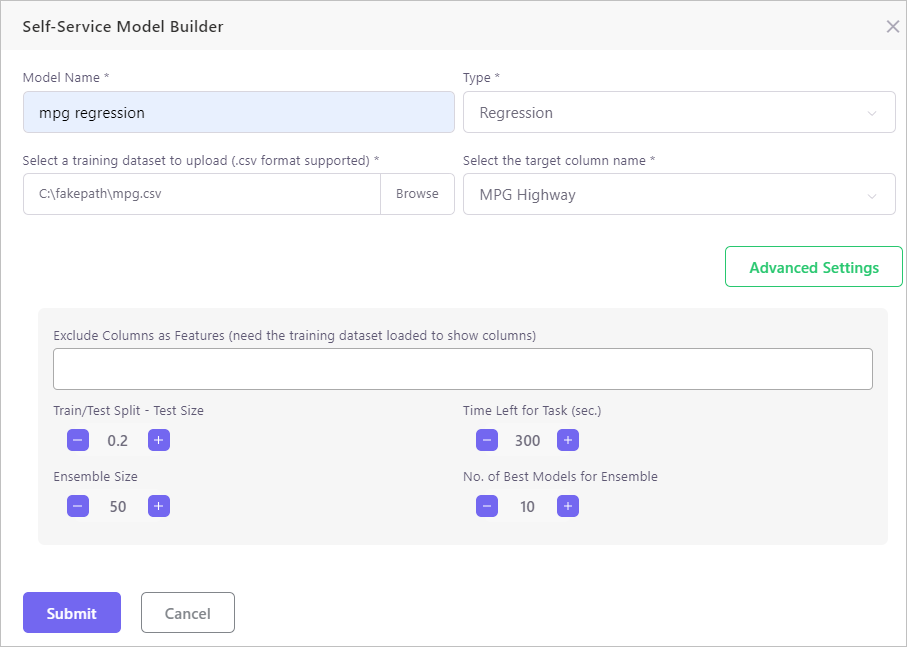
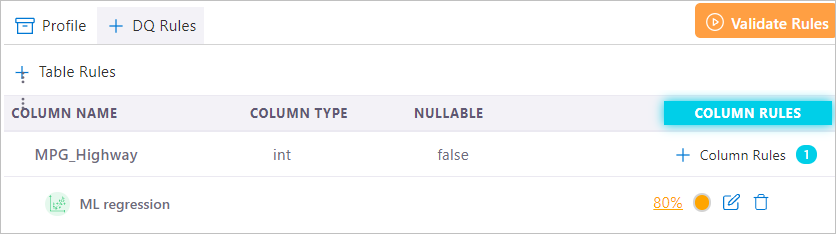
Once submitted, the model will be trained backend. When the model is ready for use, DQ analysts can create an “ML Regression” rule on the datasets with the same schema of the “Golden Dataset”.

The execution of the rule load the model and predict the target column (dependent variable) and calculate the tolerant range of expected value. When a field value falls out of the expected value range, that value is treated as inconsistent.
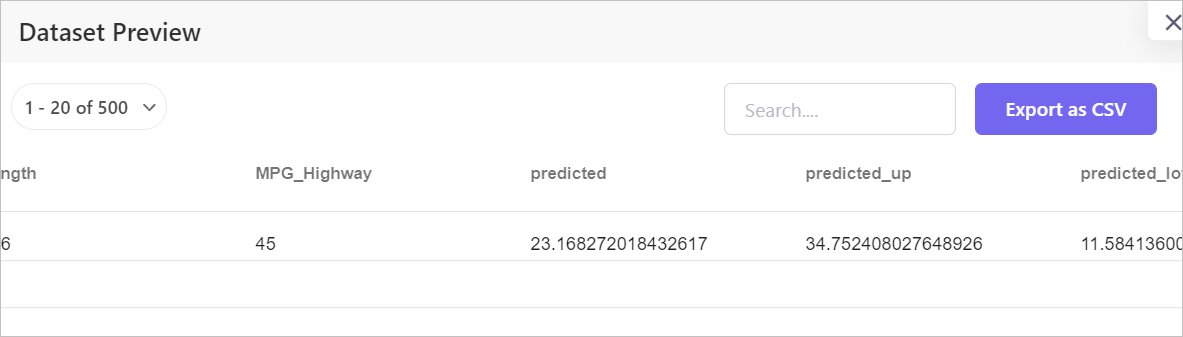
The decisive factor for this idea to work is the accuracy of the models trained by the self-service builder. Auto-sklearn is able to choose the most performant algorithms and the most optimal hyperparameters based on the cross-validation results automatically. Therefore, the quality of the “Golden Dataset” decides whether the trained model would work or not.
Anomaly Detection
Anomaly detection is a popular use case for commercial AI-enabled data quality monitoring software. It logs the history of data quality observations and detects the anomaly. Anomaly detection is an effective technique to raise awareness of data quality issues. I have also implemented an anomaly detection feature in the dqops app. The approach I have been using is to conduct a time-series analysis of the historical observations using fbprophet package and check whether or not the current observation is in the predicted value range.
PII Detection
Strictly speaking, data privacy is a regulation issue instead of a data quality issue. However, PII handling is often put into the data quality assurance process and treated as a data clean task. In dqops app, I created a PII detection rule that can be applied to a text column and detect any person name. The implementation of PII detection rule is rather simple with SpaCy package.
