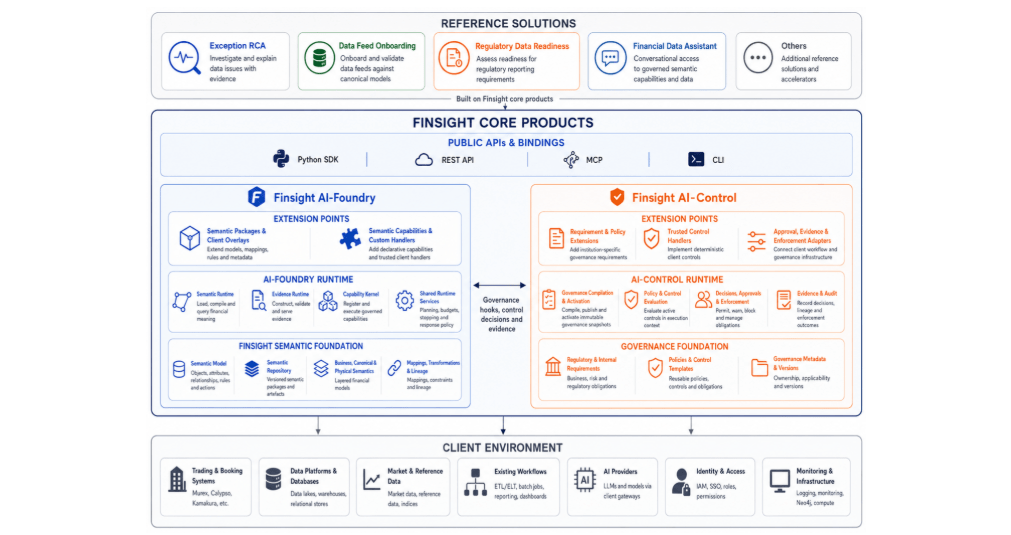
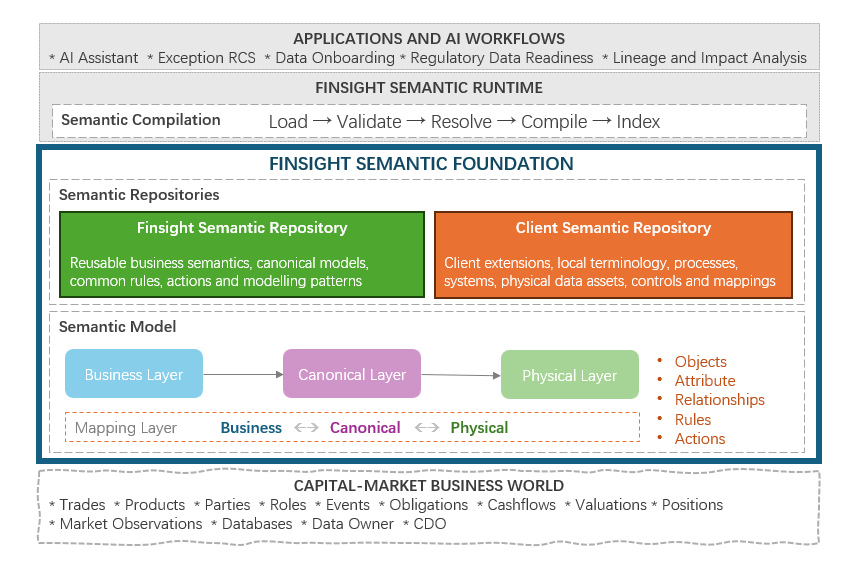
The previous article discussed Finsight AI-Foundry and the foundations required to make financial meaning, evidence and reusable capabilities available to AI applications. This article focuses exclusively on Finsight AI-Control. As with the previous article, it is not intended to be a user guide or a detailed product manual. Formal documentation covering configuration, APIs, administration and … Continue reading AI-Native Financial Data Foundation (40): Finsight AI-Control — Governance and Runtime Control for Financial AI






You must be logged in to post a comment.