Microsoft claims Azure Storage providing both high availability and strong consistency. It sounds good but obviously violates the CAP theorem as the ‘P’ (network partitioning) is not avoidable in the real world. In theory, you can only achieve either high availability or strong consistency in a distributed storage system. I have done a bit of research and found out the way how Azure Storage walks around the CAP theorem.
The figure below shows the high-level architecture of Azure Storage (from the SOSP paper authored by Microsoft product team)

Azure Storage stores data in Storage Stamps. Each Storage Stamp physically consists of a cluster of N racks of storage nodes. Each rack is built as a separate fault domain. There are three functional layers in each Storage Stamps, Front-Ends, Partition Layer and Stream Layer. The Stream Layer is where the data is stored and it can be thought of as a distributed file system layer with “Streams” can be understood as ordered lists of storage chunks, namely Extents. Extents are the units of replication that are distributed in different nodes in a storage stamp to support fault tolerance. Similar to Hadoop, the default replication policy in Azure Storage is to keep three replicas for each extent.
For Azure Storage to successfully cheat over the CAP theorem to provide high availability and strong consistency at the same time under the condition of network partitioning, the stream layer needs to be able to immediately response requests from client and the reads from any replica of the extent needs to return the same data. In the SOSP paper, Microsoft describes their solution implemented in Azure Storage as layered design with stream layer responsible for high availability and partition layer responsible for strong consistency. However, I have to admit I was confused with the explanations presented in the SOSP paper.
Instead, I found the core idea behind Azure Storage implementation is rather simple, i.e. offering strong consistency at the cost of higher latency, in the other words, enforcing data replication on the critical path of writing requests. The figure below shows the journey of a write request at the stream layer.
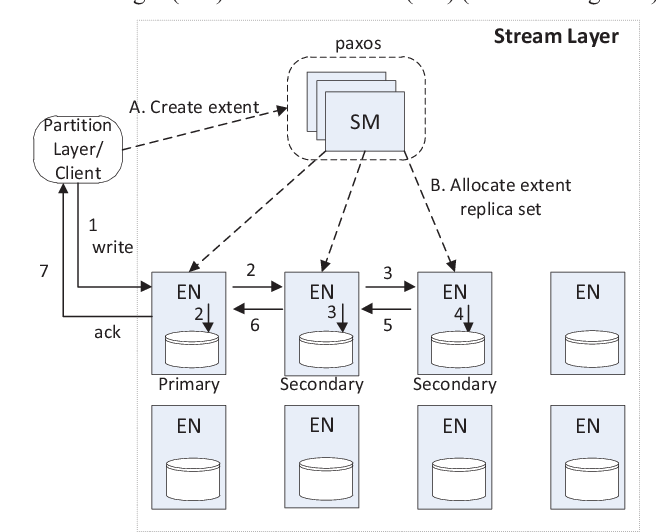
In a nutshell, extents are append-only and immutable. For an extent, every append is replicated three times across the extent replicas in a synchronous mode. A write request can only marked as success when all of the writes to all replicas are successful. Compared to asynchronous replication that is often used to offer eventual consistency, the synchronous replication will no doubt cause higher write latency. However, the append-only data model design should be able to compensate that.
It is worth to mention that the synchronous replication is only supported within a storage stamp. The inter-stamp replication still takes asynchronous approach. This design decision is understandable as having geo-replication on the synchronous critical write path can cause much worse write latency.

