
The last blog post explains the Aggregation strategy for generating physical plans for aggregate operations. I will continue with this topic to look into the details of the physical aggregate operators supported by Spark SQL.
As explained in the last blog post, a logical aggregate operator can be transformed into a physical plan consisting of multiple physical aggregate stages. The Aggregation strategy plans the physical aggregate plan depending on the type of aggregate expressions.

For each physical aggregate stage, a physical aggregate operator is generated. The diagram below describes the logic the Aggregation strategy takes to choose a physical operator. Compared to a sort-based aggregate operator, a hash-based aggregate operator is preferred as it does not require additional sorting operation as a prerequisite. Especially, the HashAggregateExec operator uses off-heap memory for storing the aggregate buffer hash map which offers reduced GC.

To qualify for being able to use the HashAggregateExec, the aggregateExpressions extracted from the aggregate logical plan cannot contain any aggBufferAttribute with the immutable data type. Here is the list of mutable data types supported by Spark.

If any aggregateFunction in the aggregateExpressions is a TypedImperativeAggregate (which uses user-defined java object as internal aggregation buffer) and the useObjectHashAggregation flag is set to true, the ObjectHashAggregateExec operator is selected.
When the aggregateExpressions do not meet the conditions for being able to use the HashAggregateExec operator and the ObjectHashAggregateExec operator, the SortAggregateExec operator is selected. In addition, the HashAggregateExec operator and ObjectHashAggregateExec operator will fall back to using sort-based aggregation when there is no efficient memory for the hash-based operators.
In this blog post, I will explain the SortAggregateExec first, and cover the HashAggregateExec operator and the ObjectHashAggregateExec operator in the next blog post.
SortAggregateExec
The SortAggregateExec uses a sort-based aggregation approach that requires the rows to be sorted by the grouping key so that that the rows with the same grouping key are placed next to each other. Therefore, the aggregate operator just needs to loop through all rows one by one and aggregate based on the grouping key.
Let’s take an example to walk through how the SortAggregateExec operator works. At the high level, a dataset needs to be first reshuffled by the grouping key to have the rows with the same grouping key are placed into the same partition. Within each partition, the rows will need to be sorted by the grouping key so that the rows with the same grouping key are placed next to each other.
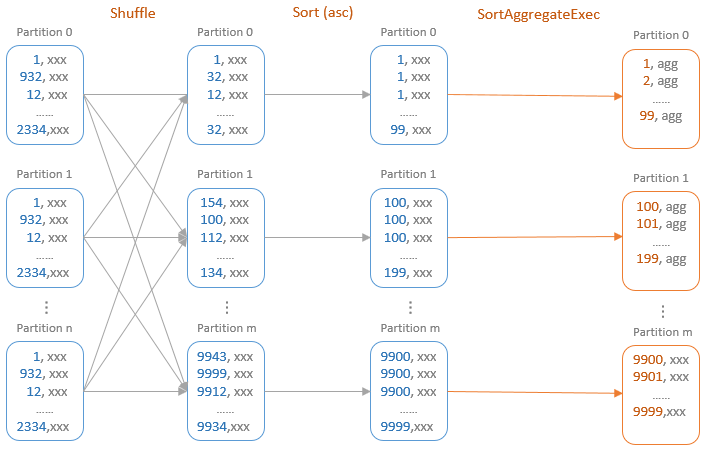
Once the rows are sorted, the aggregate operator can start to process the rows for the physical aggregation. Internally, for each partition, a SortBasedAggregationIterator is created for evaluating the aggregate functions.

The SortBasedAggregationIterator creates a buffer row to cache the aggregated values. Unlike the hash-based aggregation which requires a hash map to hold all of the grouping key -> aggregate value buffer pairs, the SortBasedAggregationIterator just need to hold the aggregate buffer for the current aggregate group. Therefore, one row will be sufficient. When the data types of all the aggBufferAttributes are mutatable, the buffer row is created to use the off-heap memory, otherwise use the on-heap memory.
When an instance of the SortBasedAggregationIterator for a partition is being constructed, the inputIterator parameter brings in the iterator of the input rows sorted by the previous stage. The aggregate buffer row, sortBasedAggregationBuffer, is created and initialised.

The next method of the SortBasedAggregationIterator calls the processCurrentSortedGroup method which starts to get rows to process from the input iterator until it finds a new group (i.e. the next row of the input iterator has a different grouping key).

As the example below shows, the rows with the group key “1” are processed one by one by the processCurrentSortedGroup method. For each row, the processRow method is called to update the buffer values using the corresponding aggregate functions. After one row is processed, the processCurrentSortedGroup method checks whether or not the next row is in the current group. If so, move to the next row in this group.

When the current group is processed, the output row is generated for the current group.

The aggregate buffer will then be reset for processing the next key group.

This process will repeat until all the input rows are processed.

The SortAggregate diagram is rather misleading:
1. It doesn’t show the partial agg step. As with hash aggregation, records are aggregated within existing partitions first, then shuffled and then aggregated again
2. Spark uses hash partitioning between partial and final aggregation and not range partitioning. Despite not being incorrect, it is highly unlikely that partition 0 will have all the lows and partition m all the highs