
This blog post looks into Spark SQL Cache Commands under the hood, walking through the execution flows of the persisting and unpersisting operations, from the physical execution plan to the cache block storages.
Cache Commands

Spark SQL ships with three runnable commands for caching operations, including CacheTableCommand, UncacheTableCommand, and ClearCacheCommand. End-user developers or analysts can use the cache statements in their SQL query to trigger these commands.

Taking the CACHE TABLE statement as an example, it allows developers or analysts to specify the cache execution mode (eager or lazy), the cache storage level, and the SELECT query defining the cache data.


As mentioned in the previous blog post explaining the runnable commands in Spark SQL, the runnable commands are executed eagerly. The caching operations are internally conducted using persist operator which is executed lazily. Here Spark SQL cheats the eager execution of cache commands by forcing a count action after the underlying persist operation is constructed. Users can roll back to lazy execution by specifying the LAZY parameter in the Cache statement.

StorageLevel
One of the most important parameters for caching is StorageLevel, which is used to control the storage mode of the cached data. A StorageLevel internally encapsulates a list of storage settings, including whether allowing to use disk, whether allowing to use memory, whether allowing to use off-heap memory, whether storing deserialized cache data, and the number of replications.

Spark SQL provides a list of pre-defined StorageLevel objects, each of them is based on a specified combination of the storage settings. For example, the default and the most commonly used MEMORY_AND_DISK storage level has both _useDisk and _useMemory set as true while has _deserialized set also as true for not stored serialised cache data.

The selection of a storage level depends on the cached data size and speed to access requirements.
- _useDisk – supports large cached data size, but low access performance
- _useMemory – supports small cached data size, but high access performance
- _deserialized – supports smaller cached data size, but higher access performance
- _useOffHeap – supports similar cached data size, but higher access performance
In addition, the _replication defines whether to replicate the cached partitions on multiple nodes to improve the availability.
Cache Execution
Internally, caching operations are executed lazily, which means the persist method for the caching operations are not immediately executed, but instead, it is only executed when an action is triggered. In this section, I explain the cache execution at two stages: the planning stage and the actual executing stage. In addition, I will also walk through the execution flow of the uncaching operations and also explain the cache release mechanism.
Cache Planning
When a Cache SQL statement is submitted, the Spark SQL query engine parses the statement and creates a CacheTableCommand logical plan for it. The CacheTableCommand is then executed by the ExecutedCommandExec physical operator by calling the run method of the CacheTableCommand. The run method then calls the cacheTable method of the catalog interface of the current sparkSession, which then triggers the cachequery method of the CacheManager.
The CacheManager maintains the list of cached plans in the CachedData type as an immutable sequence. A CachedData instance holds a cached logical plan and an InMemoryRelatoin instance created for this logical plan. The InMemoryRelation instance references the CacheRDDBuilder instance created for building the RDD of the CachedBatch, RDD[CachedBatch] which is the data structure for a batch of cached rows. The buildBuffers method of the CachedRDDBuilder defines the logic for executing the logical plan, batching the result rows for caching and returning the RDD[CachedBatch]. The persist method of RDD[CachedBatch] is called at this moment. However, as persist operation is lazily executed, the Cache RDD building process is just defined but not physically executed yet.

The persist method of the cache RDD calls the persistRDD method of SparkContext and also set the storageLevel attribute of the RDD to the storage level specified by the query. The persistRDD method registers registered the RDD to be persisted in the persistentRdds map of the SparkContext. The persistentRdds map keeps track of all persisted RDDs within the current SparkContext. SparkContext opens the getRDDStorageInfo developer API which can be called to return information about the information of the cached RDDs, such as storage mode, used space, and number of cached partitions.
Cache Execution
A Spark action needs to be executed in order to trigger the physical execution of the caching process. The action internally triggers the execution of the ResultTask instance, which calls the iterator method of the RDD overs the partition of the executor where the task is being executed. The iterator method checks whether the storageLevel attribute of the RDD. If the stoargeLevel attribute is a value other than NULL, that means this is a cached RDD or the cache has been defined but not been executed yet. The getOrElseUpdate method of the BlockManager instance of the executor is called to retrieve the cached block if it exists. If the requested block does not exist, the doPutIterator method of this BlockManager instance is called to compute the block, persist it, and return the values.

The doPutIterator method persists the cache block according to the given storage level. If the given storage level supports to use memory, depending on whether the storage level support serialisation or not, the putIteratorAsValue method of the MemoryStore instance for saving deserialised data or the putIteratorAsBytes method for saving serialised data is called. When the data to cache is too big to fit into the memory, if the given storage level supports to use disk, persist the data to the disk store instead. If the storage level does not support to use disk, the persist operation is failed and the input data iterator is returned back to the caller so that the caller can decide the alternative solutions.
If only disk is supported by the given storage level, the data to cache is firstly serialised and then put into the local disk store.
After an RDD is physically persisted, the information of the cached RDDs can be found under the “Storage” section of the Spark UI.

Uncache
When an uncache statement is submitted, an UncacheTableCommand logic plan is created and is executed by the ExecutedCommandExec operator. Running the UncacheTableCommand follows the same execution chain as the CacheTableCommand but calls the uncache*** methods instead of the cache*** methods, as shown in the following chart.

At the end of the execution chain, the StorageLevel of the RDD is set to NULL and the reference of the RDD is removed from the persistentRdds registry in the SparkContext. At the same time, the BlockManagerMaster is informed to remove all the blocks of the RDD, which sends the RemoveRDD message to executors for removing the cache data from memory and/or disks.
Cache Release
When an RDD is not used anymore and there is no strong reference of it exists, the GC process will release the resources allocated for this RDD. When the RDD (the definition of a dataset excluding the actual data) is removed, its cached data is not useful as well, but it still occupies the storage resources, either memory or disk. Spark provides the ContextCleaner, which manages the release of unused cache resources. The ContextCleaner contains a referenceBuffer queue, which is backed by a SetFromMap of CleanupTaskWeakRference type objects. When GC collects an unused RDD, a weak reference of this RDD is added into the referenceBuffer queue.
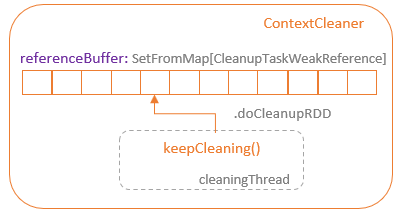
ContextCleaner runs the keepCleaning method in a separate thread, which loops through the referenceBuffer and picks up the weak reference to the RDD. The doCleanupRDD method of the ContextCleaner is called with the id of the RDD, which executes the unpresistRDD method to remove the strong references to the RDD cache so that the GC can release the RDD cache.

