
This blog post continues the Delta Lake table write joruney into the parquet file write internal.

As described in the last blog post, a ParquetOutputWriter instance is created and call the Parquet API for writing a partitoin of the Spark SQL dataframe into Parquet file. From this point on, the Delta table write journey steps into the Parquet terrortory.

To understand this blog post, some fundemental knowledge about Parquet format is required, such as Row Group, Column Chunk, and Page. You could find tons of articles covering those topics from Google, so I wound not repeat those in this blog post. If need, please search for them by yourself.
Parquet Write Initiation
The ParquetOutputWriter object executed within a Spark executor task creates a Parquet ParquetOutputFormat object and called the getRecordWriter method.
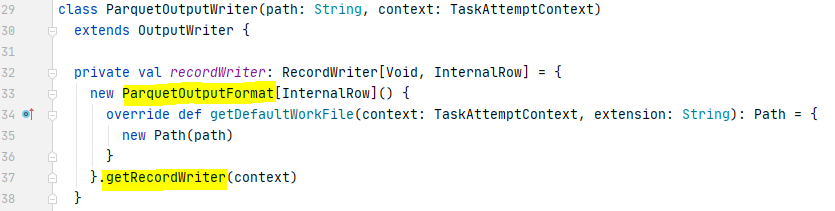
The getRecordWriter method mainly initialise the parquet file write context, including the creation and initialisation of the ParquetWriteSupport object, the Spark SQL implementation of Parquet WriteSupport that writes Spark SQL Catalyst InternalRow as Parquet messages, the ParquetFileWriter object that encapsulates the file-level operations, the ParquetRecordWriter that is the entry to record writing operations, and the MemoryMananger that keeps a global context of the memory usages of parquet writers.
The start method of the ParquetFileWriter object is also triggered at this moment that writes the Magic Number to file output stream to mark the start of the Parquet file.
At the time when the ParquetRecordWriter object is created, an InternalParquetRecordWriter object is created and the initStore method is called that initialises a new column store and a new page store.
Parquet Record Writer
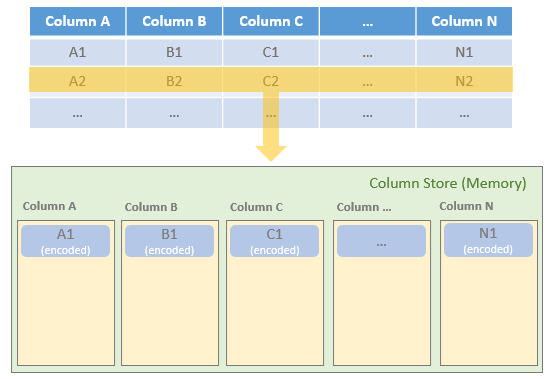
Despite the data would be ultimately stored in Parquet column by column, the Spark SQL dataframe data is written into Parquet row by row.
The ParquetRecordWriter object created in the getRecordWriter method above offers a write method that is called to write a single record into Parquet. In each SQL executor task, an Iterator[InternalRow] of the current partition of dataframe data is looped through and the ParquetRecordWriter write method is called for each InternalRow one by one.
The ParquetRecordWriter write method then calls the ÏnternalParquetRecordWriter write method that triggers the ParquetWriteSupport write method, which is defined in Spark SQL framework for converting Spark SQL dataframe InternalRow to the message format consumable by Parquet API.

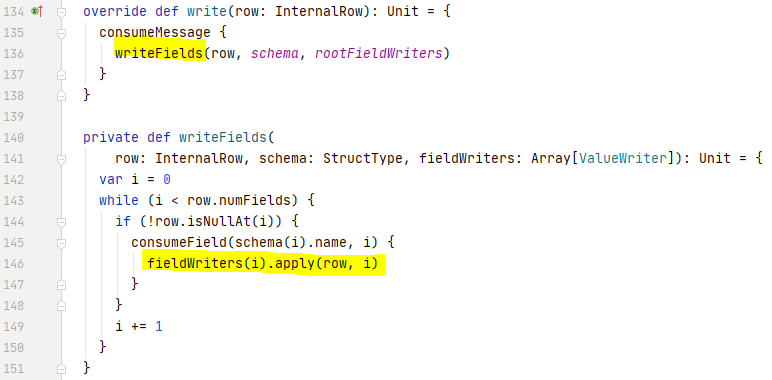
The ParquetWriteSupport write method splits a InternalRow into fields and write the fields from the row one by one.
On the Parquet side, the Parquet record consumer, which hosts a column writer for each column of the input dataframe, calls the column writer of the current filed, and trigger the corresponding ValuesWriter write method to encode and write the value into the column store. ValuesWriter is the base class to implement an encoding for a given column. Here is a list of encoding implementation supported by Parquet. As encoding is an important topic with columnar storage, I am going to dedicate a separate blog post to dive into the Parquet encoding implementations.
The column writer also writes the repetition level and definition level of a field. Because Delta table mainly stores flatten schema at this moment, the implementation of nested schema in Parquet is out of scope of this blog post.
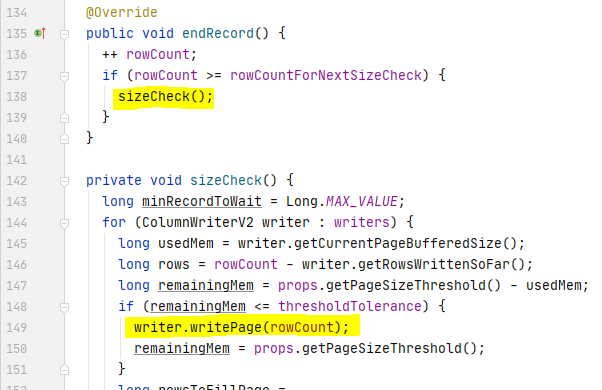
After the pre-defined minimum number of rows have added into the column store, the column store starts to check whether or not the size of the added (and encoded) column values (for a column) is reaching the predefined page size threshold.
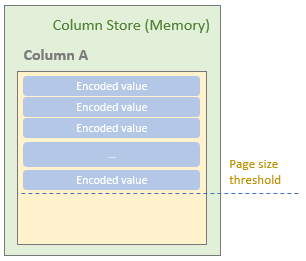
If it reaches the page size threshold, the ColumnWriter of the current column in the column store will write the page into page store, which internally is an array list of byte[] (List<byte[]>). Each page contains a page header that includes the metadata of the page, such as page size (compressed and uncompressed), value count, null value count, and min/max values.
Parquet compresses data at the page level. If a compress format such as snappy is specified, a page will be compressed before written into the page store.
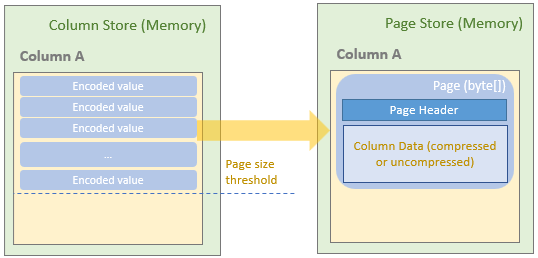

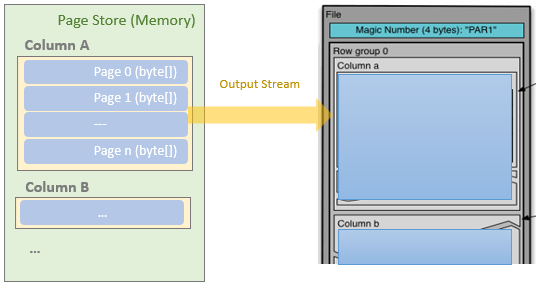
After that, the Parquet dismisses the current column store and page store and reinitialise new stores, and continue to read the remaining dataframe rows and repeat the process.
FileMetaData Write
Apart from the PageHeader metadata stored in each page, the parquet file also encapsulates the file schema and RowGroup metadata for each row group. They are appended to the end of the Parquet file. I am going to dive into the details and usage of those metadata when I cover the Parquet file reading part.

