Spark SQL Catalyst provides a rule-based optimizer to optimise the resolved logical plan before feeding it into the SparkPlanner to generate the physical plans. An experienced programmer can write more efficient code because they have a set of rules, design patterns and best practices in their brain and can choose a suitable one depending on the situation. A rule-based optimizer plays the same role, which maintains a set of predefined rules and applies those rules to transform a logical plan to an optimised status expected by those rules.

Similar to the Catalyst Analyzer, the Optimizer is inherited from the base RuleExecutor, which override the batches property with the set of logical plan optimisation rules shipped with Spark SQL Catalyst. In addition, Catalyst Optimizer was designed with extensibility as one of the core requirements. It is pretty simple to add a new optimizer rule: create a rule object that extends the root Rule[LogicalPlan] parent class, implement the apply method, and use pattern matching to define the sub-plan to replace, and implement the optimisation logics, and finally add the rule object into the extendedOperatorOptimizationRules.

The optimisation rules are organised and executed in batches. For Spark 3.0.0, there are 19 batches defined and executed by Catalyst Optimizer, including:
- Eliminate Distinct
- Finish Analysis
- Union
- OptimizeLimitZero
- LocalRelation early
- Pullup Correlated Expressions
- Subquery
- Replace Operators
- Aggregate
- Operator Optimization
- Early Filter and Projection Push-Down
- Join Recorder
- Eliminate Sorts
- Decimal Optimizations
- Object Expressions Optimization
- LocalRelation
- Check Cartesian Products
- RewriteSubquery
- NormalizeFloatingNumbers
Those batches are executed in order. Some of the batches are only needed to execute once with one run, but others need to go through multiple runs until reaching a fixed point (more details can be found in my previous blog post).
Optimizer is the core of the Spark SQL Catalyst, and the Optimizer rule is the core of the Optimizer. In this blog post (and possibly a few more considering the number of Optimizer rules to cover), I will walk through the batches and explain how the Optimizer rules work. For most of the rules, I will provide one or more examples, each of which consists of the SQL query the rule is applied, the Analyzed Logical Plan (before the rule is applied), and the Optimized Logical Plan (after the rule is applied).
Batch – Eliminate Distinct
The “Eliminate Distinct” batch only includes one rule, EliminateDistinct, which remove useless DISTINCT for MAX and MIN. The “Finish Analysis” batch is supposed to be the first batch to execute during the optimisation phase. However, The EliminateDistince rule has to be applied before the RewriteDistinctAggregates rule in the “Finish Analysis” batch.
EliminateDistinct
The Distinct operation does not make any difference to the query output when it is applied inside a MAX or MIN agg function. The EliminateDistinct rule is applied to eliminate the useless Distinct operations.
Here is an example demonstrating how this rule works. As you can see, the distinct operator is in the analyzed logical plan but is removed from the optimized logical plan by the EliminateDistinct rule.



Batch – Finish Analysis
The “Finish Analysis” batch is the batch for logical plan post-analysis processing. This batch needs to be executed before all other optimisation batches (except “Eliminate Distinct” as mentioned above).
EliminateResolvedHint
The EliminateResolvedHint rule extracts query hints from the analysed logical plan, moves the HintInfo to the associated Join operators (for the SparkPlanner to select the corresponding join strategy), and finally eliminate the ResolvedHint operators.
As the example shows below, the hint information is moved to the join operator and the ResolvedHint operator is removed from the optimised logical plan.



EliminateSubqueryAliases
The SubqueryAlias will not be useful after the logical plan is analysed. The EliminateSubqueryAliases rule removes the SubqueryAlias operator.


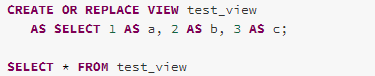
EliminateView
Same as SubqueryAlias operators, the View operators is only used for highlighting which part of an analysed logical plan is generated from a view at the analysis stage. The EliminateView rule is used to remove the views.


ReplaceExpressions
The ReplaceExpressions rule replaces unevaluable expressions with semantically equivalent expressions supported by the current environment. This rule is mainly for providing compatibility with other databases.
RewriteNonCorrelatedExists
The RewriteNonCorrelatedExists rule uses ScalarSubquery to replace the non-correlated Exists subquery. A non-correlated subquery refers to a query within a query that does not reference any columns from the parent query.
As the example shows below, the Exists subquery has been replaced with a ScalarSubquery, which selects 1 row of the subquery and check whether or not the result returned is null.



Here is what the query looks like after applying The RewriteNonCorrelatedExists rule.

ComputeCurrentTime
When multiple calls are made for getting the current date and time in a single query, the ComputeCurrentTime rule is needed to compute the current date and time once and ensure all the references of the current date and time get the same value.
GetCurrentDatabase
The GetCurrentDatabase rule retrieves the current database name from the metadata catalog associated with the current session.
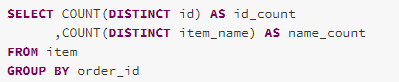
RewriteDistinctAggregates
The RewriteDistinctAggregates rule rewrites an aggregate query, which aggregates the distinct values of a column, into a two-stage aggregation. The first stage de-duplicates the distinct paths and aggregate the non-aggregate paths and the second stage aggregates the distinct groups.


ReplaceDeduplicateWithAggregate
The deduplication operations can be implemented with aggregate in a way that the grouping keys and the agg values are all the attributes involved in the deduplication operations


Batch – Union
The “Union” batch only includes one rule, CombineUnions, which combines two or more adjacent Union operators into one. The “Union” batch is arranged to execute before other major Optimizer rules to avoid the other rules to insert operators between two adjacent Union operators that might cause more iteration. On the other hand, the other rules might make two separate Unions operators adjacent, the CombineUnions rule will be called again in the “Operator Optimisation” batch.
CombineUnions



Batch – OptimizeLimitZero
The “OptimizeLimitZero” batch is a single rule batch as well, which includes the OptimizeLimitZero rule. This batch handles the case where GlobalLimit and LocalLimit have the value 0. The GlobalLimit 0 and LocalLimit 0 nodes imply an empty result set, therefore no data is needed to actually read from a data source. In this case, the OptimizerLimitZero rule will prune the node below the GlobalLimit or LocalLimit.
OptimizeLimitZero

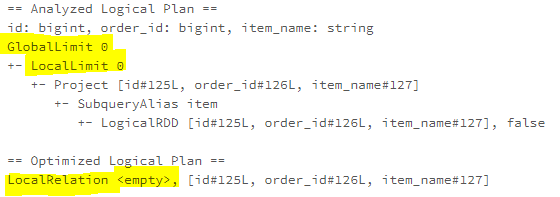
Batch – LocalRelation early
The “LocalRelation” batch will be executed twice, one before the major Otimizer rules and one after. This is the first one that is executed to simply the logical plan for avoiding potential heavy optimizer rules in the later batches. For example, the ConvertToLocalRelation rule in this batch can convert a Filter(LocalRelation) query to LocalRelation only that eliminate the optimisations of the filter operator which can trigger heavy optimizer rules in the later batches.
ConvertToLocalRelation
The local operations on a LocalRelation, such as Project, Limit and Filter, are executed locally in driver instead of executors. The ConvertToLocalRelation rule processes those local operations before the “Operator Optimization” batch so that the query plan is simplified with those local operations eliminated from later optimisation and execution.
From the source code of the ConvertToLocalRelation rule, we can see that this rule takes a logical plan, find the local operators (Project, Limit, Filter) on a LocalRelation, and creates and returns a new LocalRelation object that has the local operators applied.

The “LocalRelation” batch also includes the PropagateEmptyRelation rule. However, based on my personal understanding, an empty relation can only be generated by other optimizer rules. Therefore, the PropagateEmptyRelation rule is only applicable in the later run of the “LocalRelation” batch. It makes more sense to explain this rule when discussing that batch, so I leave this rule in the later blog post.
Batche – Pullup Correlated Expressions
The “Pullup Correlated Expressions” batch only includes the PullupCorrelatedPredicates rule.
PullupCorrelatedPredicates
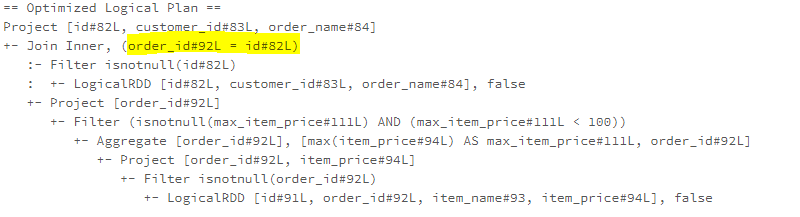
The PullupCorrelatedPredicates rule is one of the Optimizer rules for optimising correlated scalar subqueries, which pulls all outer correlated predicates from a subquery and moves them to the upper level. Another rule involved in the correlated scalar subqueries is the RewriteCorrelatedScalarSubquery rule, which rewrites the correlated subquery to the join. The RewriteCorrelatedScalarSubquery rule is executed in the “Operator Optimization” batch, which will be covered in the following blog posts.
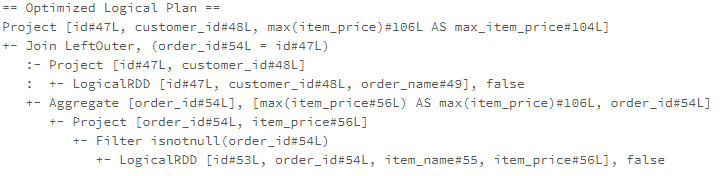
Take the following correlated subquery as example, the subquery references the attribute order.id from the outer query in the filter clause.


From the optimized logical plan, we can see the correlated predicate has pulled up to the top-level in the Join operator (the RewriteCorrelatedScalarSubquery rule is also applied to the logical plan, therefore, the subquery is also converted to join in the final optimized logical plan)
Batch – Subquery
The “Subquery” batch is expected to apply subquery-targeted optimizer rules recursively to optimise subqueries. For Spark 3.0.0, only one batch is included in this batch, the OptimizeSubqueries rule.
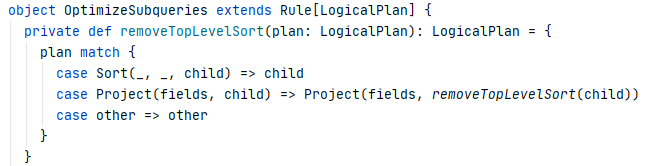
OptimzeSubqueries
The OptimizeSubqueries rule optimises all the subqueries inside expressions. For Spark 3.0.0, only one subquery optimisation case is implemented, which removes Sort operator from a subquery, because the results produced by a subquery are un-ordered.