
Spark Structured Streaming reuses the Spark SQL execution engine, including the analyser, optimiser, planner, and runtime code generator. QueryExecution is the core component of the Spark SQL execution engine, which manages the primary workflow of a relational query execution using Spark. IncrementalExecution is a variant of QueryExecution that supports the execution of a logical plan incrementally, which is the backbone of the micro-batch based streaming query executions.
Internally, the IncrementalExecution is a sub-class of the QueryExecution, which is designed to reuse the core analysis, optimisation, and planning components and rules that are initially developed for executing one-off batch queries. In the meantime, the IncrementalExecution extends the QueryExecution to enable the update of the execution plan with a new batch of data and maintain query states between batches.
Before looking into the IncrementalExecution, let’s briefly revisit the QueryExecution (more details can be found from my Spark SQL Query Engine deep dive series).

For a one-off batch query, the QueryExecution first analyses the parsed query, resolving the relation and attribute names and validating the syntactical correctness of operators and expressions. The resolved logical plan is then optimised by the Spark Catalyst Optimizer, a rule-based optimizer that applies a set of pre-defined rules to transform a logical plan to an optimised status expected by those rules. The optimised logical plan is then converted into one or more candidate physical plan based a set of predefined Spark query planning strategies. The best physical plan is expected be selected based on a cost model approach. The runtime code is then generated from the selected physical plan and is executed in Spark cluster.
Here, I refer this type of query execution described above as “one-off” which implies that all the data to process is available to process and is processed in one query execution lifecycle. All the data is read, transformed and write in one go and no intermediate status needs to be maintained. The “incremental” query execution is different where the input data will continuously reach the source and become available to process. Compared to the “one-off” query execution, the “incremental” query execution needs to handle some additional requirements, such as updating the execution plan with a new batch of source data and maintaining the states of stateful operations between micro-batches.
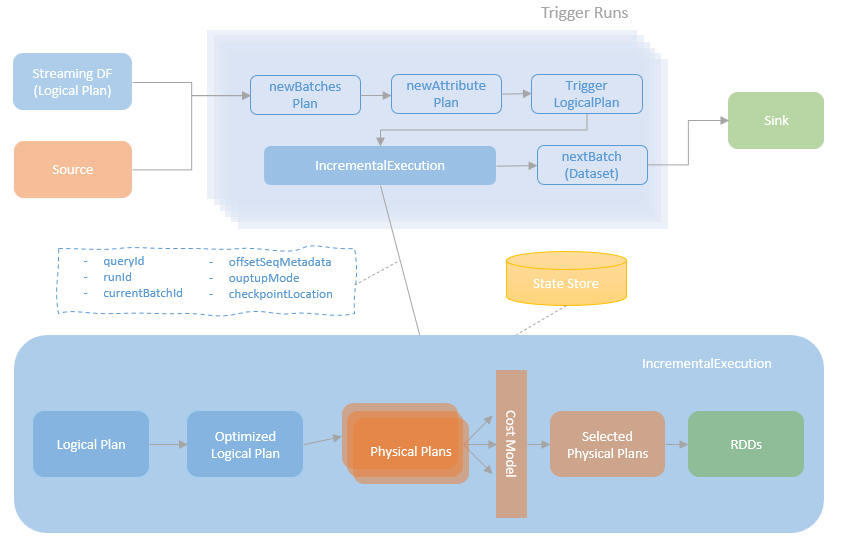
For the Spark micro-batch based “incremental” query execution, a streaming query is created and is continuously running that makes repeated attempts to run micro batches as data arrives. The logical plan of the streaming query is created, analysed and initialised before the streaming query starts to run. When a streaming query is started, for each micro-batch run, the new batch data and source attributes are rewired to the logical plan, and a new IncrementalExecution instance is created using the updated logical plan. As mentioned above, the IncrementalExecution is a sub-class of the QueryExecution. It reuses the primary workflow of the QueryExecution and extend it with additional streaming processing specific rules and strategies.
Analysis
Spark Structured Streaming reuses the existing analysis rules of the Spark SQL Catalyst Analyzer for resolving the attributes and types defined in the streaming query. More details of the Spark SQL Catalyst Analyzer can be found in my previous blog post.
In addition, Spark Structured Streaming extends the analysis rules for checking whether the operations of a streaming query can be executed in incremental mode or not, such as distinct aggregations, chained aggregations, and DDL commands. Spark Structured Streaming also provides analysis rules for validating the streaming output mode of the specific queries, For example, “Complete” output mode is not supported when there is no streaming aggregations on the streaming dataframe.
Rewiring
This is an additional step, exclusively for incremental streaming execution, that replaces source data and rewires source attributes of the logical plan for each micro-batch execution. After a streaming query is started, each source is checked for new data arrived. For the new data available, depending on the max batch size per trigger limit, the new micro-batch is constructed and the dataframe represents the micro-batch data is returned. The streaming query replaces sources in its logical plan with new micro-batch data to get the newBatchesPlan and also rewire the newBatchesPlan to use the new attributes that were returned by the sources to get the newAttributePlan. With the rewired logical plan, an IncrementalExecution instance is created for the current micro-batch execution.
Optimisation
Spark Structured Streaming reuses the existing optimisation rules of the Spark SQL Catalyst Optimizer for optimizing the logical plan. More details of the Spark SQL Catalyst Optimizer can be found in my previous blog post.
Physical Planning
The IncrementalExecution class extends the SparkPlanner of the QueryExecution to include the extra planning strategies for planning physical execution of stateful operations.

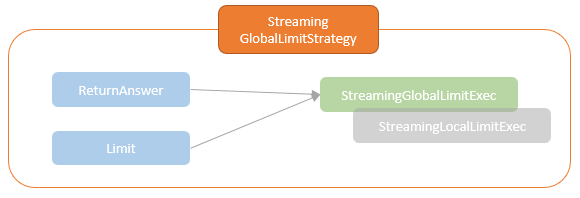
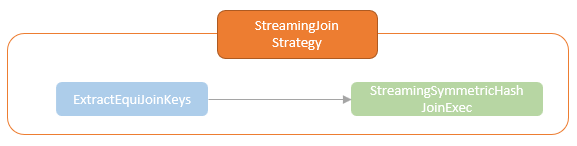
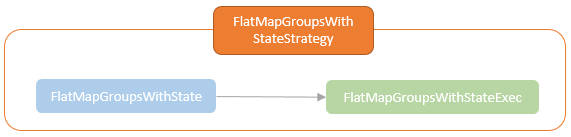
As mentioned above, processing stateful operations where intermediate states are required to be maintained across micro-batches is one of the core requirements for incremental streaming executions. Up to the Spark V3.2, six planning strategies are provided by the Spark Structured Streaming.

Those planning strategies transform platform-independent LogicalPlans to SparkPlan for executing on Spark cluster. The SparkPlans for the stateful operations implement the logical for state management. Spark Structured Streaming provides the StateStoreOps class with the mapPartitionsWithStateStore and the mapPartitionsWithReadStateStore that creates the StateStoreRDD and ReadStateStoreRDD which executes the physical write and read of the state store.
I will discuss those strategies and the related physical SparkPlans in details in the next few blog posts.



Execution Preparation
After the SparkPlanner converts the logical plan into the physical plan, a list of preparation rules needs to be executed to prepare the physical plan for execution. The Spark Structured Streaming reuses the preparation rules defined in the QueryExecution, such as EnsureRequirements which inserts the exchange or sort operators when required.
Apart from the preparation rules inherited from the QueryExecution, the IncrementalExecution also defines rules for preparing stateful operations that add the state info to the stateful operators. As mentioned above, for each micro-batch execution, an IncrementalExecution instance is created. The metadata or the streaming query and the current batch, such as runId, currentBatchId, and checkpointLocation are passed in the IncrementalExecution instance when it is created. In addition, an IncrementalExecution instance maintains an incremental integer, statefulOperatorId, and a nextStatefulOperationStateInfo method. When the nextStatefulOperationStateInfo method is called, the statefulOperatorId is auto incremented by 1 and is used along with the other metadata mentioned above for defining an StatefulOperatorStateInfo instance, which is used to identify the state store for a given operator.
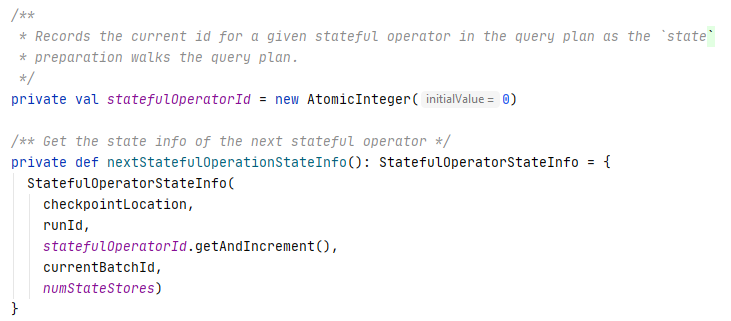
The preparation rules for preparing stateful operations walk through the query plan, pattern match the stateful operators, and call the nextStatefulOperationStateInfo method to get the state info for each stateful operators.
