
In the previous blog post, I covered the rules included in the “Eliminate Distinct“, “Finish Analysis“, “Union“, “OptimizeLimitZero“, “LocalRelation early“, “Pullup Correlated Expressions“, and “Subquery” batches. This blog post carries on to cover the remaining Optimizer batches, including “Replace Operators“, “Aggregate“, and part of “Operator Optimisation” (the largest batch with 30+ rules).
Replace Operators
Some SQL operators, such as Except or Intersect, can be implemented with existing operators. There is no need to create those operators from scratch with repetitive transformation logic. The “Replace Operators” batch includes the rules for replacing those operators in a logical plan with the existing operators.
- ReplaceIntersectWithSemiJoin
- ReplaceExceptWithFilter
- ReplaceExceptWithAntiJoin
- ReplaceDistinctWithAggregate
- RewriteExceptAll
- RewriteIntersectAll
ReplaceIntersectWithSemiJoin
The ReplaceIntersectWithSemiJoin rule replaces an Intersect operator in a logical plan with a left-semi join operator. An Intersect clause in SQL is used to combine two datasets by returning only the rows existing in both datasets. This logic can be implemented with a left-semi join operation.
Taking the following query as an example, from the comparison of the analysed logical plan and the optimised logical plan, we can see that the Intersect operator is replaced with a LeftSemiJoin with join condition on each Project attribute and a Distinct operation is made to the output of the left-semi join.


The optimised logical plan can be represented as the query below.

ReplaceExceptWithFilter
An Except SQL operator is used to combine two datasets by returning the rows available in the left-side dataset but not in the right-side dataset, which can be understood as a subtract operation of two datasets. When the datasets involved in the Exceptor operator are purely transformed with filtering, the Except operator can be replaced with a filter combining the left-side dataset filtering condition and the flipped right-side dataset filtering condition.

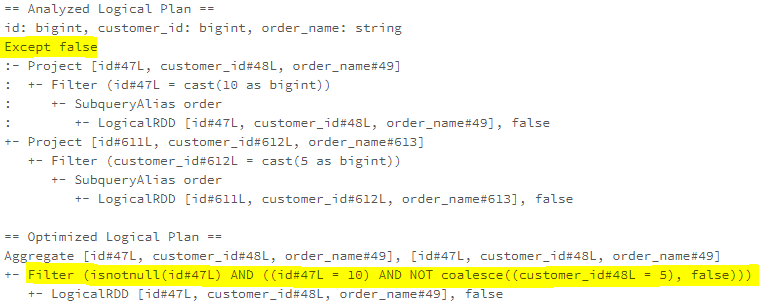
The optimised logical plan can be represented as the query below.

ReplaceExceptWithAntiJoin
The Except operator can also be implemented using LeftAntiJoin.


The optimised logical plan can be represented as the query below.

ReplaceDistinctWithAggregate
The Distinct operator can be implemented using Aggregate operators, which uses the projection attributes as the grouping key.



The optimised logical plan can be represented as the query below.

RewriteExceptAll
An Except All SQL operator returns all rows (including duplicates) from the left-side dataset that are not in the right-side dataset. The RewriteExceptAll rule rewrites the Except All operator using the following algorithm:
- Add an extra column ‘vcol’ to the datasets of the Except All operator. The value of ‘vcol’ column for the left-side dataset as 1, and the value of ‘vcol’ column for the right-side dataset as -1.
- Union the two datasets and group the unioned dataset by the top-level projection attributes and sum(vcol).
- Return the rows from the grouped dataset when the sum(vcol) > 0.
- For each returned row, replicate the row by this row’s sum(vcol) times.


The optimised logical plan can be represented as the query below.

RewriteIntersectAll
Intersect All operator returns the rows that are in both left-side and right-side datasets. Unlike the Intersect operator, the Intersect All operator does not remove duplicates. The RewriteIntersectAll rule rewrites the Intersect All operator using the following algorithm:
- Add two extra columns, ‘vcol1’ and ‘vcol2’ to the datasets of the Intersect All operator. For the left-side dataset, set ‘vcol1’ as true, and set ‘vcol2’ as null. For the right-side datset, set ‘vcol1’ as null, and set ‘vcol2’ as true.
- Union the two datasets and group the unioned dataset by the top-level projection attributes and count(vcol1), count(vcol2).
- Return the rows from the grouped dataset when the both count(vcol1) and count(vcol2) > 1.
- For each returned row, find the smaller number between the count(vcol1) and count(vcol2) and replicate the row by that number’s time.

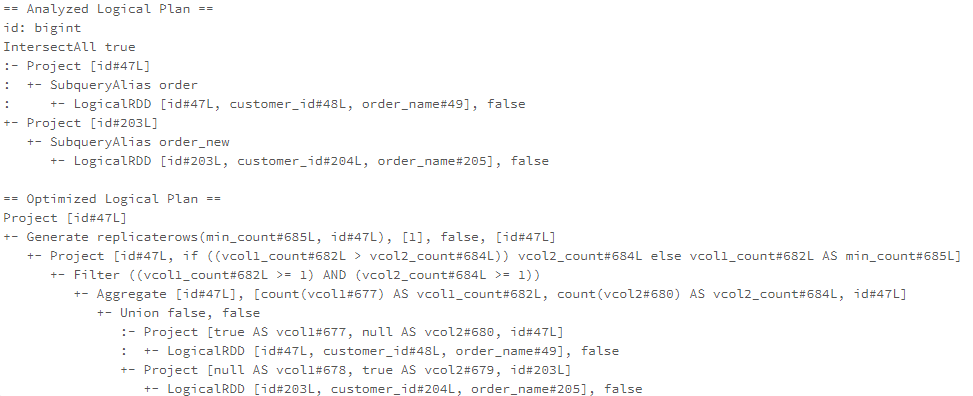
The optimised logical plan can be represented as the query below.

Batch – Aggregate
The “Aggregate” batch is created for optimising aggregate operations in a logical plan. For Spark 3.0.0, two rules are included in this batch, the RemoveLiteralFromGroupExpressions rule and the RemoveRepetitionFromGroupExpressions rule.
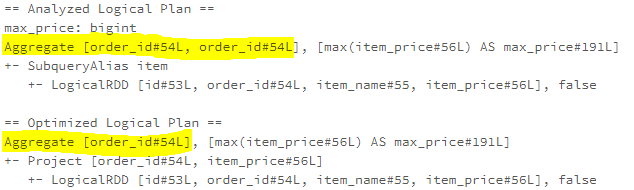
RemoveLiteralFromGroupExpressions
The literals in group expressions make no effect on the final result but instead make the grouping key bigger. The RemoveLiteralFromGroupExpressions rule removes the literals from the group expressions.
As the example shows below, the literal “a” and the value from the current_timestamp function (which has already been converted to be a constant by the ComputeCurrentTime rule in the earlier batch) are included in the group key of the aggregation operation. However, they makes no effect on the aggregation grouping. Therefore, the RemoveLiteralFromGroupExpressions rule removes them from the optimised logical plan.



RemoveRepetitionFromGroupExpressions

Batch – Operator Optimisation
The first category of Optimizer rules I am going to introduce is operator push down rules. The operator (such as Project and Predicate) push down is one of the most effective optimisation strategies, which try to reduce the size of data for processing as earlier as possible.
PushProjectionThroughUnion
When a Union operator is the child of a Predict operator, the PushProjectionThroughUnion rule pushes the Predict operator to both sides of the Union operator. As the example shows below, the project of each union branch reads all the three columns, col1, col2, col3, while the top-level project only needs col1, col2.

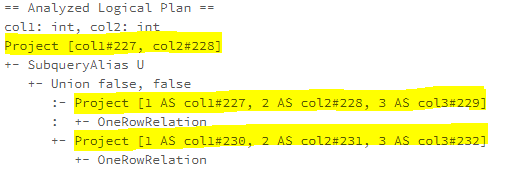
After the PushProjectionTroughUnion rule is applied, the top-level Project has been pushed down to the Union braches and the column, col3, which is not used at the top-level projection has been pruned.
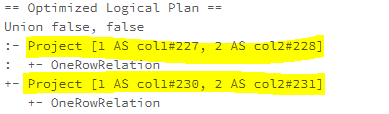
ReorderJoin
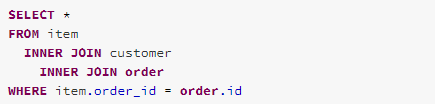
The ReoderJoin rule reorders the joins and pushes all the conditions into join so that the filtering can occur as early as possible. As the example below shows, the joins (“INNER JOIN customer” and “INNER JOIN order”) has been reordered and the “INNER JOIN order”, which filter condition is applied to, has moved to inner, and the Filter condition has been pushed into it.
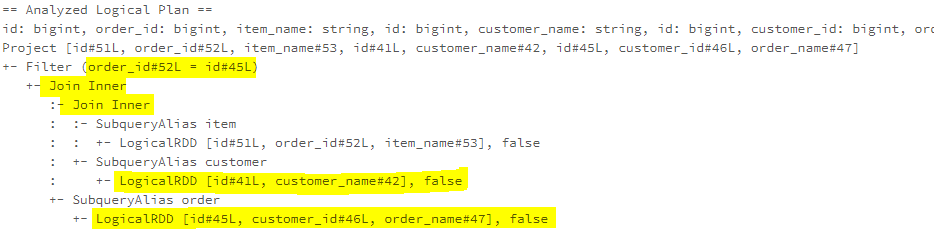

If all of the joins have at least one condition applied to, as the example shows below, the order of joins will not be changed, and only the filter conditions will be pushed into the respective Join operators



EliminateOuterJoin
The EliminationOuterJoin rule is used to eliminate outer joins when there are predicates that can filter out the rows with null values. Here is the logic for replacing the outer join with other types of joins.

Take the following query as an example,, for a Right Outer Join, the left-side (“item” of the join will be filled with nulls for that non-matched right-side (“order”) rows. However, if there is a filter condition, such as “item.id > 1”, that makes the Right Outer Join an Inner Join. Therefore the RightOuter Join operator can be replaced as an Inner Join



This is an example that replaces a Full Outer Join with an Inner Join when there is filter condition on both sides.



Another example for replacing Full Outer Join with a Left Outer Join while there is a filter condition on the left side.



PushDownPredicates
The PushDownPredicates rule is an important rule that pushes predicates down to as close as the data source. A predicate defines a logical condition with the result as True or False for filtering rows in the data source. The PushDownPredicates rule actually wraps three other rules, CombineFilters, PushPredicateThroughNonJoin, and PushPredicateThroughJoin. I will explain the PushPredicateThroughNonJoin rule and the PushPredicateThroughJoin rule in this blog post, and introduce the CombineFilters rule when I cover the “Operator Combine” category

PushPredicateThroughNonJoin
The PushPredicateThroughNonJoin rule is for the cases where the Predicates are pushed down through a non-join operator.
Case 1 – Push predicate through Project

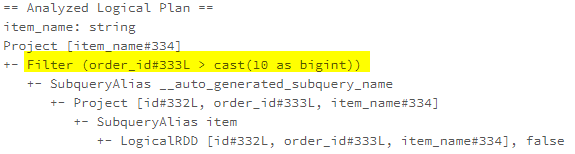




Case 3 – Push predicate through Window
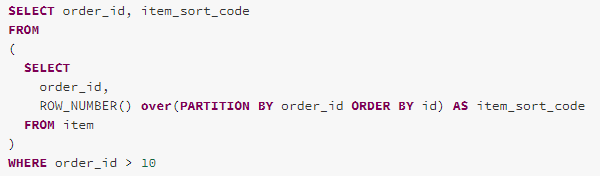


Case 4 – Push predicate through Union
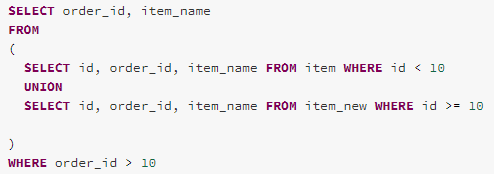


Case 5 – Push predicate through all other supported operators
Apart from the four cases mentioned above, the PushPredicateThroughNonJoin rule also supports the following operators.

Here is an example for pushing predicate down through the Pivot operator.
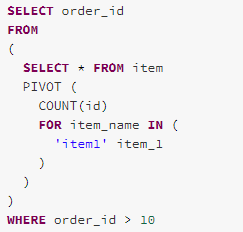
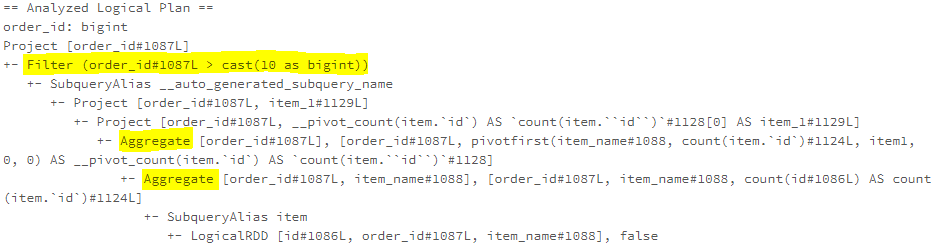

PushPredicateThroughJoin
The PushPredicateThroughJoin rule is for the cases where the Predicates are pushed down through a non-join operator.
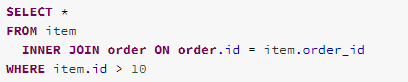
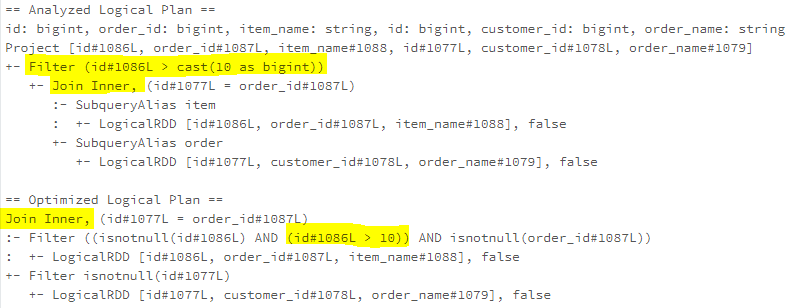
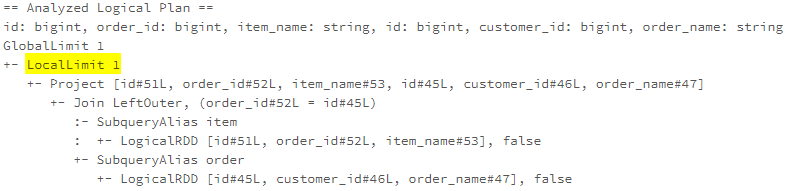
LimitPushDown
The LimitPushDown rule pushes the Limit operator through Join or Union operators.


ColumnPruning
The ColumnPruning rule is used for eliminating the reading of unneeded columns from the logical query plan. Taking the following query as an example, the max agg function has been applied to the s_date column and produced the max_date agg value, but the max_date is not used by the top-level Project.


The ColumnPruning rule removes the aggregation calculation on the max_date in the query plan and pushed the Project down through the Aggregate operator

InferFiltersFromConstraints
The InferFiltersFromConstraints rule adds additional filters from an operator’s existing constraint. For example, the isnotnull function is applied for adding an isnotnull filter to an existing filter.

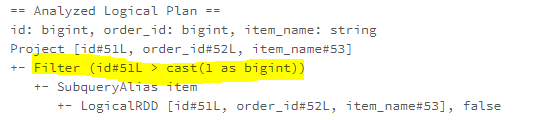

The isnotnull filter can also be added to the children of a Join operator.



