
As mentioned in the last blog post, a Spark Catalyst query plan is internally represented as a tree, defined as a subclass of the TreeNode type. Each tree node can have zero or more tree node children, which makes a mutually recursive structure. TreeNode type encapsulates a list of methods for traversing the tree and transforming the nodes.

QueryPlan, the parent for both LogicalPlan and SparkPlan, is a subclass of TreeNode type. That means the logical plan and the spark plan involved in the Spark SQL query execution process are recursive tree structures. The process for transforming a query plan from one stage to another stage, e.g. from a resolved logical plan to an optimized logical plan, is the process of applying rules for transforming the nodes or subtrees.

Internally, a Catalyst rule for transforming logical plan needs to extend the abstract base Rule class which defines an apply(plan: TreeType): TreeType method. All the logical plan analyzer rules and the optimizer rules have to inherit from the abstract base Rule class and override and implement the apply method with the transformation logic.
A RuleExecutor class is provided by the Catalyst for coordinating the executions of rules for a logical plan processing stage. Both the Analyzer class and the Optimizer class are a subclass of the RuleExecutor. The Analyzer class is responsible for transforming an unresolved logical plan to a resolved logical plan, and the Optimizer class is responsible for transforming a resolved logical plan to an optimized logical plan, before feeding into the physical plan processing pipeline.

As you can see, there is no RuleExecutor subclass for the physical plan processing stage. Strictly speaking, the physical plan is not part of Spark Catalyst. The Spark Catalyst is designed as a platform-independent SQL optimizer, which in theory should be able to be used for any platform. The physical plan is Spark-specific implementation, which is part of Spark SQL. That’s the reason why Catalyst is located at a separate package org.apache.spark.sql.catalyst. A SparkPlan is converted from an optimised logical plan by spark strategies [SparkStrategy type], which will be covered in detail in the following blog posts.
A RuleExecutor contains a batches property, which is overridden by the subclasses, Analyzer or Optimizer, for defining a sequence of rule batches, each of them contains a list of Catalyst rules.

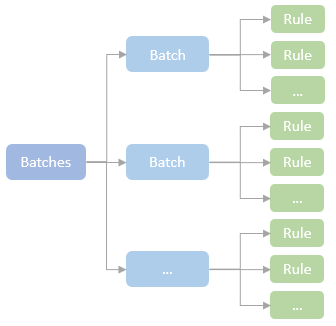
The RuleExecutor executes Catalyst rules batch by batch. There might be multiple runs to one batch until it reaches a fixed point where the tree stops evolving. The RuleExecutor moves to the next batch only when the current batch finishes all the runs. The multiple runs of a batch to a fixed point allows the rules to be designed to be simple and self-contained but still eventually have larger global effects on a tree.
Each RuleExecutor provides an executeAndTrack method, which can be called to run the rule batches. As mentioned in the last blog post, the executeAndTrack methods of Analyzer and Optimizer have been called in the QueryExecution for starting the logical plan transformation.
The executeAndTrack method triggers the execute method of RuleExecutor, which contains the batches run loop.

For each rule execution in a batch run, Catalyst will use pattern matching to test which part of a query plan tree the rule applies to, and apply the rule to transform that part. I will dig deeper into the Analyzer rules in the next blog post.
