dqops Data Quality Studio (DQS) is one of my R&D projects I have been doing during my spare time. I plan to note down some tips & tricks I use in this project in the future blog posts from time to time.
Databricks is one of the main data services that the dqops DQS is going to support. This blog post notes down the approach for querying Databricks database schemas using the “Databricks SQL Connector for Python” library.

The “Databricks SQL Connector for Python” library supports to query Databricks databases through Spark Thrift Server (STS) that allows JDBC/ODBC clients to execute SQL queries over JDBC or ODBC protocols on Apache Spark. A similar approach has been used by dqops DQ studio to connect to on-premises Spark cluster with jaydebeapi library. However, the “Databricks SQL Connector for Python” library simplifies the setup and does not need the installation of JDBC driver on the client environment.
Setup
The setup of the “Databricks SQL Connector for Python” library is simple. You just need to include the python library ref “databricks-sql-connector==0.9.0” in the requirements.txt on the client environment from where your code needs to query the Databricks databases. Alternatively, you can manually install the library using “pip install databricks-sql-connector“
Databricks Connection
The “Databricks SQL Connector for Python” library uses the same connections interface as the other JDBC/ODBC python libraries, such as pyodbc and jaydebeapi. That makes it very easy to build the Databricks connector on top of the existing dqops data connection framework that I have built, based on the open-source sodasql Dialect module, to support different types of data repositories, such as Azure Database, Databricks Azure Synapse, and Snowflakes.
To create a Databricks connection, we just need to import “sql” module and run the “connect” function (line 11-15 in the following figure).

The “connect” function requires the hostname and http_path of the thrift server deployed in the target Databricks cluster and also the Databricks access token. The hostname and http_path can be found in the “Advanced Options” section of the cluster setting page.

Databricks access token can be set in the “User Settings” page of the Databricks workspace.
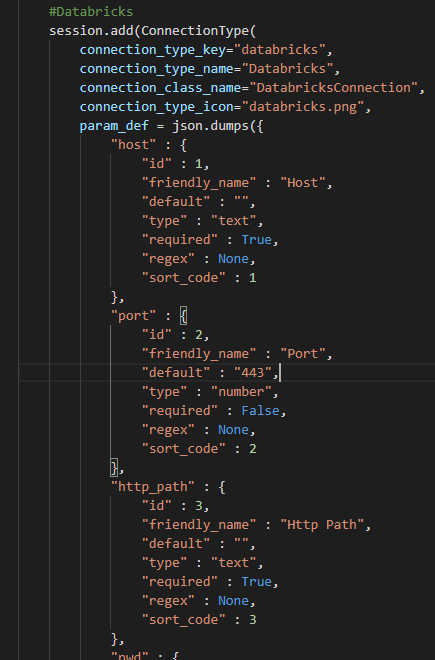
As dqops DQS needs to allow end-users to create and test connection based on a specific data source type, a UI component has been created that generates the data connection form based on predefined connection type metadata.
 |  |
Query Metadata
After the connection instance is created, we can run sql commends against the Databricks databases using the “execute_sql” function with the sql statement passing in as the parameter.

Spark provides a set of SQL commands to read database/table/column metadata. In dqops DQS, the “SHOW TABLES” command is used to read the list of tables in a specified database, and the “DESCRIBE TABLE” commend is used to read column name and type in a data table.

More Spark sql commends related to metadata can be found here.
The snapshot below shows the metadata UI in the dqops DQS that is built using the Databricks SQL Connector for Python.

