
As promised in the last blog post, I am going to dedicate a whole blog post to explore Parquet encoding, focusing on finding answers to the following questions:
- Why does Parquet using encoding?
- What encoding algorithms are used in Parquet?
- How does Parquet implement encoding?
- How does Parquet choose encoding algorithms?
Why does Parquet using encoding?
Short answer: Parquet encoding makes the data size smaller, therefore the IO volume is smaller and the memory usage is smaller.
Despite extra CPU costs being required for decoding the Parquet data, it is still a good deal to trade off CPU costs for IO costs. For modern computers, it is much cheaper to increase computing power compared to increasing the IO performance. Especially for big data workload, IO is the bottleneck of the data query performance.
Memory is cheap, very cheap actually. The costs of memory to concern is not on the memory size but instead on the memory scan costs. A smaller data size reduces the memory footprint of the data required for your query so that reduces the RAM to scan.
In another perspective, encoding is more efficient when it is applied to a columnar storage format such as Parquet that the data with the same date type is stored together.
What encoding algorithms are used in Parquet?
Here I am going to use a simple dataset as an example to explain the encoding algorithms.
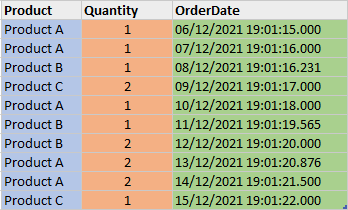
Dictionary Encoding
Dictionary encoding builds a dictionary of all the distinct values of a column and then replaces the column values with the indexes of the distinct values in the dictionary. Like the example shown below, the “Product” column holds the names of the products. With Dictionary encoding, all the distinct product names are added into the “Product” dictionary, each of which has a unique index referring to it. The column now holds the index of the product name in the dictionary instead of the actual product name.
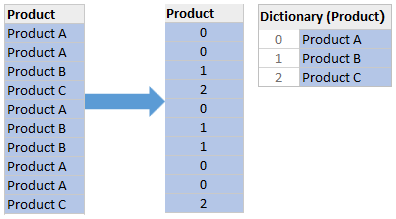
As you might find that the performance of Dictionary encoding depends on the cardinality of the column. The lower the cardinality, the compression ratio of the column is higher, and the size of the encoded data is smaller. Therefore, you could normally expect the dictionary encoding of a “Gender” column to achieve a higher compression ratio than the dictionary encoding of a “Postcode” column.
You could also expect a similar query performance of the different data types once they have been encoded with dictionary encoding, no matter the string, integer or date data type. The size of the column values (which are now index values) is the same. The only difference is with the size of the dictionary. As the cardinality of the column is same and so the unique values in the dictionary are the same, the workloads of scanning the column would be similar for different data types.
Run Length Encoding (RLE)

Run Length Encoding (RLE) replaces repeating values in a column with the number of contiguous rows with the same value. In our example, the “Quantity” column hosts the repeated data. Instead of encoding the values back to back, RLE counts the same value that appears consecutively and stores the number of repetitions and the value.
The performance of RLE depends on the repetition pattern of a column. The more rows with the same value stored consecutively, the higher the compression ratio the RLE can achieve. On the other hand, RLE could perform pretty badly with the frequently changing values of a column. The encoded column could be even bigger than the unencoded column. Therefore, the sorting of a column makes a very big difference in the compression ratio. In addition, the cardinality of the column also plays a big role in the RLE efficiency. One extreme example is the column with a unique constrain where there is no repeated data at all.
RLE encoding could also be used as a supplement of the Dictionary encoding. The Dictionary encoding converts column values to the integer type of indexes and the RLE encoding could further compress the column if the original column shows a repetition pattern.
Delta Encoding
Delta encoding stores the differences (deltas) between sequential data instead of the whole form of data. The idea behind this approach is that the information held by the delta data along the start point data would be enough to represent the whole form of data in the column.
Delta encoding performs better when the consecutive column values have small or constant variations. One good example is the time-series data column. DateTime data type is normally stored in milliseconds internally which occupied 64 bits for each column value. The deltas could occupy much fewer bits for small variations and the large constant variations can be further processed to only store the differences between deltas.

How does Parquet implement encoding?
As discussed in the previous blog post, the implementations of the ValuesWriter abstract class conducts encoding and value writing to the column store. The implementations of the encoding in Parquet need to inherit from the ValuesWriter.
Dictionary Encoding
DictionaryValuesWriter (inherited from the ValuesWriter class) and its subclasses for each Parquet primitive data type are the Dictionary encoding implementation in Parquet.

Dictionary encoding supports all the primitive data types in Parquet. For each primitive data type, Parquet creates a dictionary values writer subclass. Parquet is able to choose the corresponding dictionary values writer against the current column data type.
Let’s look into one of the dictionary values writer subclasses, such as PlainBinaryDictionaryValuesWriter, to see how Parquet conducts dictionary encoding.
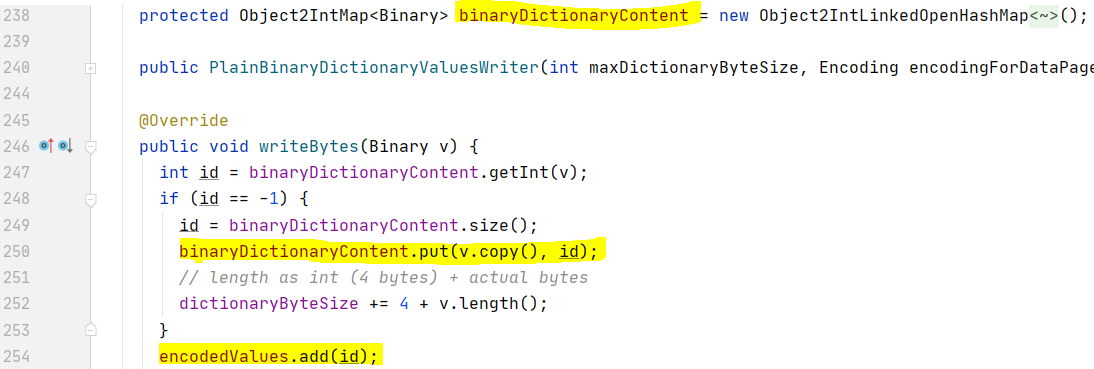
Firstly, a hash map (fastutil) is created to be the dictionary: the key of the hash map stores a unique column value, and the value of the hash map stores the index of the column value in the dictionary.
In the value write method, the dictionary is first looked up to check whether or not the column value to write already exists. If the column value does not exist yet, it will be added to the hash map first. If the column value already exists in the dictionary, the index of this column value in the dictionary will be added into the encoded values list which will be flushed into the data page. The hash map for the dictionary will be flushed into the dictionary page.
When the number or the size of the unique column values exceeds the allowed thresholds, the values writer will fall back to a predefined fallback encoding method (which is configured in the ValuesWriter factory).
Run Length Encoding (RLE)
Parquet implements the RLE encoding in the RunLenthBitPackingHybridEncoder, which is used by the RunLengthBitPackingHybridValuesWriter for encoding and writing column values. This encoder only supports only Dictionary indices, Boolean values and repetition and definition levels in the data pages.
The RunLenthBitPackingHybridEncoder combines both RLE encoding and bit packing. When Parquet writes a column value using the RunLengthBitPackingHybridValuesWriter, the repeated value will be cached until a different value occurs. The repetitions of the repeated value will be counted. If the value is repeated more than 8 times, RLE encoding will be used with the following grammar.
rle-run := <rle-header> <repeated-value> rle-header := varint-encode((rle-run-len) << 1) repeated-value := value that is repeated, using a fixed-width of round-up-to-next-byte(bit-width) *varint-encode is ULEB0128 coding

If the condition for using RLE is not satisfied and the unprocessed column values reach 8, the bit packing is applied with the following grammar:
bit-packed-run := <bit-packed-header> <bit-packed-values> bit-packed-header := varint-encode(<bit-pack-scaled-run-len> << 1 | 1) bit-pack-scaled-run-len := (bit-packed-run-len) / 8
Delta
There are a number of implementations of Delta encoding in Parquet, including the DeltaBinaryPackingValuesWriter for Int32 and Int64, the DeltaLengthByteArrayValuesWriter and the DeltaByteArrayWriter. The ideas behind the implementations are very similar so I will only cover the DeltaBinaryPackingValuesWriter implementation in this blog post as an example.
When Parquet writes a column value using the DeltaBinaryPackingValuesWriter, the delta between this value and the previous value will be calculated. At the same time, the first and the minimum of the added values in this block batch will be cached to support the next step of the encoding.
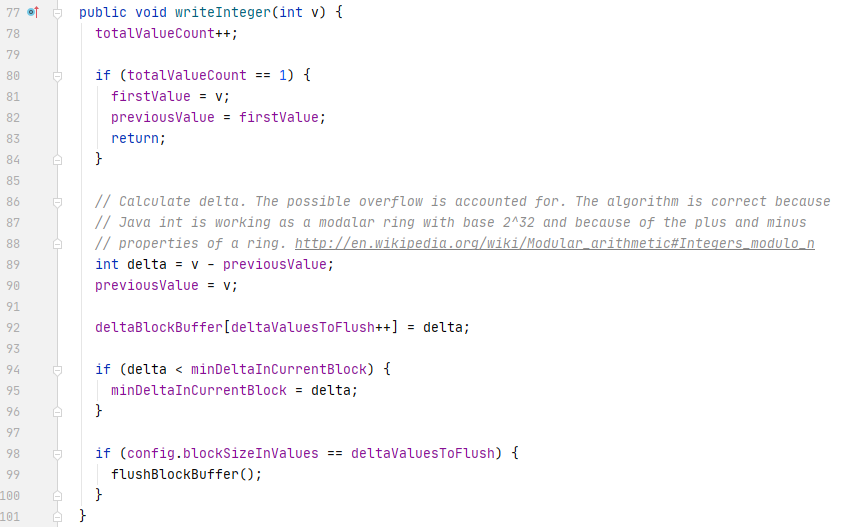
When the current block batch reaches the block size threshold, the deltas will be converted to be the difference to min delta. This will further compress the data especially when the deltas have close values. Finally, the converted deltas will be encoded into binary. You could find the header and block definition here in the Parquet official doc.
How does Parquet choose encoding algorithms?
Parquet associates a values writer, implemented with a specific encoding algorithm, to one primitive data type. When column writer writes a column value to the column store, one of the value writer implementations will be created by the values writer factory’s newValuesWriter method.
A default values writer factory, DefaultValuesWriterFactory, which handles ValuesWriter creation based on the types of the columns and the writer version, is built in the Parquet parcakge and used as default. This default values writer factory contains two implementations, one for version 1 Parquet writer and one for version 2 Parquet writer.
In each of the implementation, the newValuesWriter method defines the ValuesWriter for each primitive data type. A fallback ValuesWriter is also defined for each primitive data type. The fallback ValuesWriter will be applied when the conditions for using the main ValuesWriter are not met, such as there are too many unique values in a column to use dictionary ValuesWriter.


Custom ValuesWriter Factory
When the default values writer factory cannot meet the requirements and you want to implement your own encoding selection strategy, you could implement the ValuesWriterFactory interface and override the newValuesWriter method to define the ValuesWriter for each primitive data type.

Once you have created the customer values writer factory, you could put it on use by setting it through the withValuesWriterFactory method in the ParquetProperties Builder.

