In this blog post, I am going to explore the full delta table writing journey, from Spark SQL Dataframe to the underneath Parquet files.

The diagram above shows the whole journey of a table writing operation (some steps have been simplified or abstracted in order to make the whole table writing journey presentable in the diagram).
df.write.format("delta").save(path)
When a table writing operation is started, a new instance of the DataFrameWriter class is created. The DataFrameWriter class encapsulates the configurations and methods related to a table writing operation, such as partitioning, bucketing, and saving.
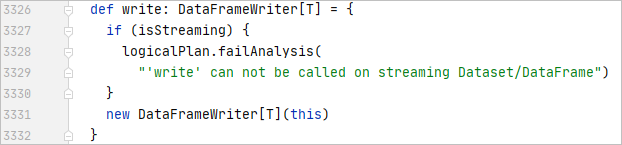
DataFrameWriter offers an interface for developers to specify the target file format. In the case of Delta Lake tables, the format needs to be set as “delta”. On a side note, Spark SQL implements data source integration in a loose-coupled, “plug-in” style. Taking the Delta Lake library as an example, the DeltaDataSource implements the DataSourceRegister trait so that it can register the alias “delta” as the format type. After the full name of the DeltaDataSource class is specified in the DataSoruceRegister meta file in the delta-core package, the DeltaDataSource can be “plug-in” the Spark SQL framework when the delta-core package is loaded.

At the time when this blog post is being written, Delta Lake supports V1 version of Spark SQL datasource. The save method of the DataFrameWrite class redirects the execution flow to the saveToV1Source method which calls the planForWriting method in the DataSource class. The SaveIntoDataSourceCommand is then called to run that eventually triggers the createRelation method in the DeltaDataSource class.
An instance of WriteIntoDelta class is created within the createRelation method. The WriteIntoDelta class is a RunnableCommand class that creates and executes a dataframe writingaction to write data file and delta metadata within an OptimisationTransaction. I will elaborate on the delta metadata writing process in a separate blog post after I cover the Delta Lake Transaction Logs. The blog post focuses on the data file writing journey.

The writing journey proceeds to execute the write method of the FileFormatWriter object that is a helper object for writing FileFomat data out to a storage location.

The write method issues a write job consisting of one or more executor tasks, each of which writes all rows within an RDD partition. The number of the executor tasks depends on the number of partitions within the dataframe to write. The tasks are executed in parallel (depending on the number of executors). For each task execution, if no exception is thrown, commits the tasks, otherwise aborts the tasks. If all tasks are committed successfully, commit the job, otherwise aborts the job. If any exception is thrown during the job commitment, the job will be aborted. Post-commit operations, such as processing statistics, will be performed if a job is successfully committed.
In each task, an instance of ParquetOutputWriter is created that bridges the Spark SQL API and Parquet API.
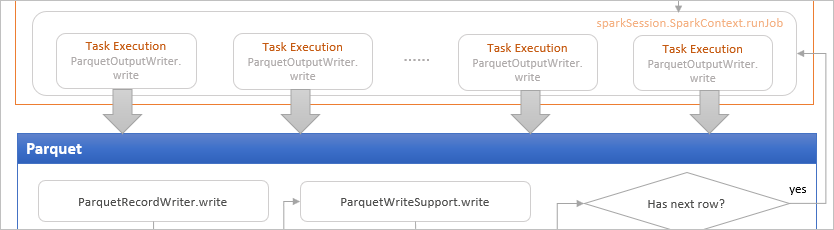
The ParquetOutputWriter instance initialises the ParquetOutputFormat object which is an instance of the ParquetOutputFormat class from org.apache.parquet.hadoop package. The parquet RecordWriter for writing data into a parquet file can be accessed from the ParquetOutputFormat object.

Now the writing journey steps into the Parquet territory.
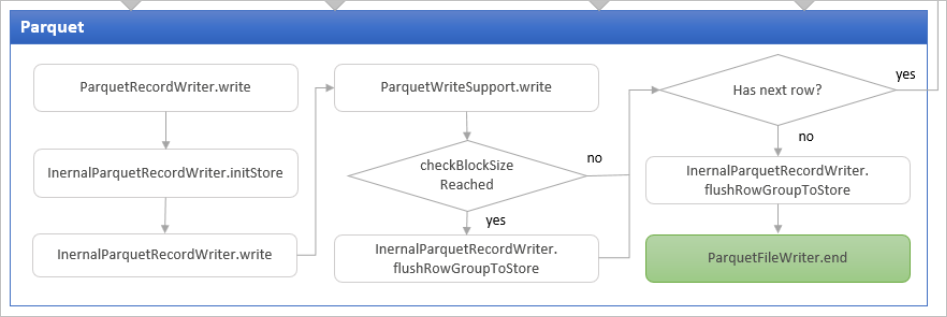
To understand Delta Lake data storage, it is very helpful to understand the parquet storage model and data writing and reading internals that covers many topics such as columnar storage format, predicate pushdown, vectorised decoding etc. I plan to cover those in the next few of blog posts.
