When analysing daily usage of a machine that can run across days, we need to split the time of a single machine running cycle into right days. As the example below shows, the second machine (D00002) run across two days and the third machine (D00003) run across three days.

To analyse the daily usage of those machines we need to transform data in the example above into the following structure.
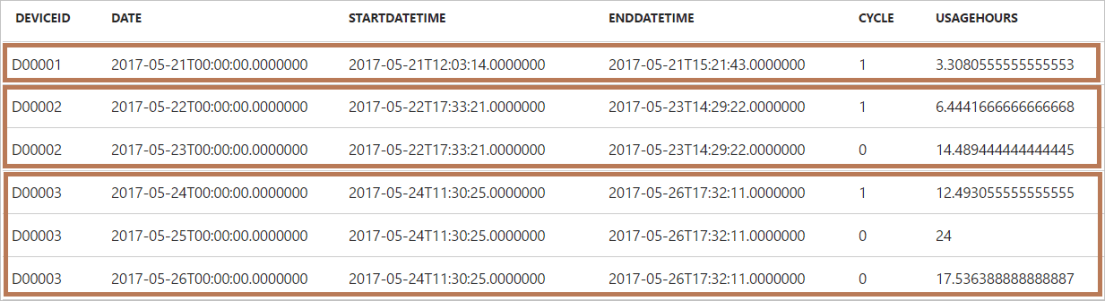
As you can see, the record of second machine that run across two days has been split into two records, one for each day. Same as the record of third machine that run across three days, the record has been split into three days. The UsageHours column stores the time the machine run on that day. For example, the second machine started to run at 17:33:21 on 22nd of May and stopped at 14:29:22 on 23rd of May. The original record of the machine running cycle will be split into two rows: the row for day on 22nd of May with UsageHours as 6.4 (between 17:33:21 and 23:59:59) , and the row for day on 23rd of May with UsageHours as 14.5 (between 00:00:00 and 14:29:22).
In this blog post, I am going to introduce how to conduct this kind of data transformation using U-SQL with Azure Data Lake Analytics (ADLA) jobs . The snapshot below shows the U-SQL code.

Firstly, we need to split the machine running cycle into the days it spans. To achieve that we need to join the machine cycle table withe a Date dimension table (here is a way to generate data dimension table using U-SQL introduced by Paul Andrew).

The join operation can give us something like:

We use the CROSS JOIN with WHERE clause to get the days within the span of cycle StartDateTime and the cycle EndDateTime (As the U-SQL JOIN does not support non-equality comparison at this moment, we cannot use INNER JOIN with ON clause)
After we split a single cycle into each day segment in the time span of the cycle, we can use the CASE statement to decide the type of the day segment (i.e. the day when machine starts, the day when machine stops, and the day(s) in middle that run the full 24 hours) and calculate the time in each day segment.
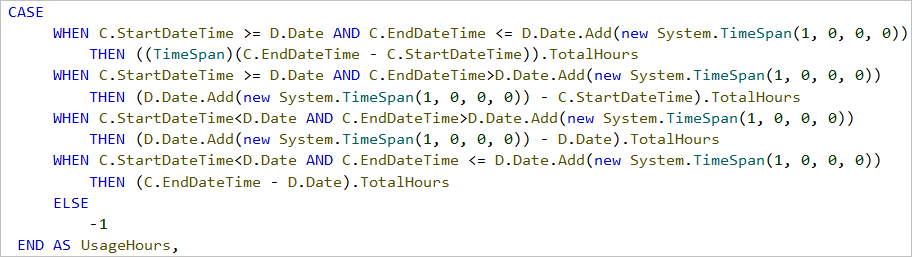
In addition, we need to use another CASE statement to flag the first day of the machine running cycle as 1 and the other days as 0. This is the trick for aggregating the count of total machine running cycles within a period. After we split a single machine cycle into multiple records, the count of records in the machine cycle table will not reflect the count of machine cycles. Therefore, we need to use the Cycle flag in each record to aggregate the count of machine cycles.

