- Introduction & Preparation
- Build ADF pipeline for dimension tables ELT
- Build ADLA U-SQL job for incremental extraction of machine cycle data
- Build ADF pipeline for fact table ELT

In the previous part we created the U-SQL job that incrementally extracts the machine cycle rows and then stores them into a staging area in the ADLS. In this part of the blog series we will create the LoadFactMachineCycle pipeline that loads the machine cycle rows from the staging area in the ADLS to the [stg].[MachineCycle] staging table in target DW database and then call a stored procedure that looks up the reference id of the dimension tables (DimMachine, DimCustomer, DimDate), create measures and load the transformed machine cycle data into the fact table, FactMachineCycle.
We start from creating this Stored Procedure, namely [stg].[uspLoadFactMachineCycle] for loading machine cycle fact table. This stored procedure joins the [stg].[MachineCycle] table and the dimension tables to get the id of those tables and calculates the machine cycle duration measure from the cycle StartDateTime column and EndDateTime column.
CREATE PROC [stg].[uspLoadFactMachineCycle] AS
BEGIN
INSERT INTO [prod].[FactMachineCycle]
SELECT S.[CycleId]
,CASE
WHEN DM.Id IS NULL THEN 0
ELSE DM.Id
END AS MachineId
,CASE
WHEN DC.Id IS NULL THEN 0
ELSE DC.Id
END as CustomerId
,Year(S.[StartDateTime])*10000+Month(S.[StartDateTime])*100+Day(S.[StartDateTime]) AS DateKey
,DATEDIFF(s, S.[StartDateTime], S.[EndDateTime]) AS Duration
,GETDATE() AS RowAdded
FROM [stg].[MachineCycle] S
LEFT JOIN [prod].[FactMachineCycle] F ON S.CycleId = F.CycleId
LEFT JOIN [prod].[DimCustomer] DC ON S.CustomerName = DC.Code AND DC.CurrentRow=1
LEFT JOIN [prod].[DimMachine] DM ON S.MachineName = DM.Code AND DM.CurrentRow=1
WHERE F.CycleId IS NULL
END
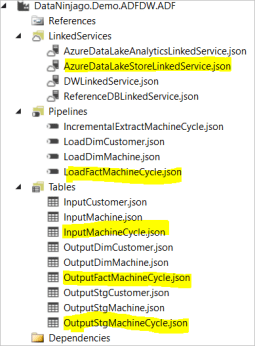
We then move on to create the ADF pipeline for the machine cycle fact table loading. the following ADF files will be crated (highlighted in yellow colour).
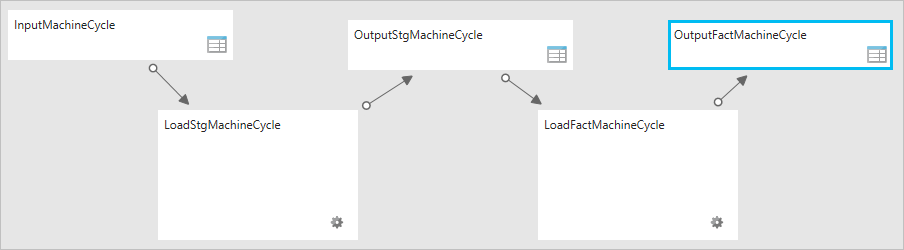
The snapshot below shows the pipeline diagram:
Firstly we need to create a linked service (AzureDataLakeStoreLinkedService) that points to the ADLS where the staging machine cycle csv files are stored.
{
"$schema": "http://datafactories.schema.management.azure.com/schemas/2015-09-01/Microsoft.DataFactory.LinkedService.json",
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "adl://{store account name}.azuredatalakestore.net",
"servicePrincipalId": "{service principal id}",
"servicePrincipalKey": "{service principal key}",
"tenant": "{tenant},
"subscriptionId": "{subscription id}",
"resourceGroupName": "{resource group name}"
}
}
}
Next, We need to create the input and output ADF tables, InputMachineCycle, OutputStgMachineCycle and the OutputFactMachineCycle. InputMachineCycle ADF table points to the staging machine cycle csv file, stgMachineCycles.scv, in the ADLS. The columns in the csv file need to be explicitly declared in the structure property. It is important to specify the type of the non-string columns, e.g., CycleId (Int32) and StartDateTime (Datetime), so that those columns can be converted from a string type in the csv file to the correct type in the DW database.
{
"$schema": "http://datafactories.schema.management.azure.com/schemas/2015-09-01/Microsoft.DataFactory.Table.json",
"name": "InputMachineCycle",
"properties": {
"type": "AzureDataLakeStore",
"linkedServiceName": "AzureDataLakeStoreLinkedService",
"structure": [
{ "name": "CycleId","type": "Int32"},
{ "name": "CustomerCode"},
{ "name": "MachineCode"},
{ "name": "StartDateTime", "type": "Datetime" },
{ "name": "EndDateTime", "type": "Datetime" },
{ "name": "EventTime", "type": "Datetime" }
],
"typeProperties": {
"folderPath": "IoT/Staging",
"fileName": "stgMachineCycles.csv",
"partitionedBy": []
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
{
"$schema": "http://datafactories.schema.management.azure.com/schemas/2015-09-01/Microsoft.DataFactory.Table.json",
"name": "OutputStgMachineCycle",
"properties": {
"type": "AzureSqlTable",
"linkedServiceName": "DWLinkedService",
"structure": [
{ "name": "CycleId" },
{ "name": "CustomerName" },
{ "name": "MachineName" },
{ "name": "StartDateTime" },
{ "name": "EndDateTime" },
{ "name": "LastModified" }
],
"typeProperties": {
"tableName": "[stg].[MachineCycle]"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
{
"$schema": "http://datafactories.schema.management.azure.com/schemas/2015-09-01/Microsoft.DataFactory.Table.json",
"name": "OutputFactMachineCycle",
"properties": {
"type": "AzureSqlTable",
"linkedServiceName": "DWLinkedService",
"structure": [
],
"typeProperties": {
"tableName": "[prod].[FactMachineCycle]"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
After the input and output ADF tables have been created we can start to build the LoadFactMachineCycle pipeline which contains two activities. The first activity, LoadStgMachineCycle, copies machine cycle data from the staging csv file stored in the ADLS to the staging machine cycle table, [stg].[MachineCycle], in the target DB. The TabularTranslator is configured to map the columns from the csv file to the staging database table. The second activity in the pipeline is a SqlServerStoredProcedure activity that calls the stored procedure we created earlier to load the machine cycle data from [stg].[MachineCycle] to the target [prod].[FactMachineCycle] table.
{
"$schema": "http://datafactories.schema.management.azure.com/schemas/2015-09-01/Microsoft.DataFactory.Pipeline.json",
"name": "LoadFactMachineCycle",
"properties": {
"description": "Load machine cycles from azure data lake store to staging table, and then call stored procedure to load the fact table",
"activities": [
{
"name": "LoadStgMachineCycle",
"type": "Copy",
"inputs": [
{
"name": "InputMachineCycle"
}
],
"outputs": [
{
"name": "OutputStgMachineCycle"
}
],
"typeProperties": {
"source": {
"type": "AzureDataLakeStoreSource"
},
"sink": {
"type": "SqlSink",
"SqlWriterTableType": "[stg].[MachineCycle]",
"sqlWriterCleanupScript": "TRUNCATE TABLE [stg].[MachineCycle]"
},
"translator": {
"type": "TabularTranslator",
"ColumnMappings": "CycleId: CycleId, CustomerCode: CustomerName, MachineCode: MachineName, StartDateTime: StartDateTime, EndDateTime:EndDateTime, EventTime:LastModified"
}
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 3,
"timeout": "01:00:00"
},
"scheduler": {
"frequency": "Hour",
"interval": 1
}
},
{
"name": "LoadFactMachineCycle",
"type": "SqlServerStoredProcedure",
"inputs": [
{
"name": "OutputStgMachineCycle"
}
],
"outputs": [
{
"name": "OutputFactMachineCycle"
}
],
"typeProperties": {
"storedProcedureName": "stg.uspLoadFactMachineCycle",
"storedProcedureParameters": {}
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 3,
"timeout": "01:00:00"
},
"scheduler": {
"frequency": "Hour",
"interval": 1
}
}
],
"start": "2017-11-10T20:00:00",
"end": "2017-11-13T01:00:00"
}
}
The snapshot below shows the [prod].[FactMachineCycle] table after the machine cycle data has been load by the ADF pipeline.

Up to this point, we have completed the end-to-end ADF pipeline that extracts data from Azure SQL DB and ADLS, and load to type 2 SCD dimension tables and fact table in a incremental loading mode.

The snapshot below shows all the visual studio files we have created for building the pipeline.




