Tree-based model can be used to evaluate the importance of features. In this blog post I go through the steps of evaluating feature importance using the GBDT model in LightGBM. LightGBM is the gradient boosting framework released by Microsoft with high accuracy and speed (some test shows LightGBM can produce as accurate prediction as XGBoost but can reach 25x faster).
Firstly, we import the required packages: pandas for the data preprocessing, LightGBM for the GBDT model, and matplotlib for build the feature importance bar chart.
import pandas as pd import matplotlib.pylab as plt import lightgbm as lgb
Then, we need to load and preprocessing the training data. In this example, we use a predictive maintenance dataset.
# read data
train = pd.read_csv('E:\Data\predicitivemaintance_processed.csv')
# drop the columns that are not used for the model
train = train.drop(['Date', 'FailureDate'],axis=1)
# set the target column
target = 'FailNextWeek'
# One-hot encoding
feature_categorical = ['Model']
train = pd.get_dummies(train, columns=feature_categorical)
Next, we train the GBDT model with the training data
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'num_leaves': 30,
'num_round': 360,
'max_depth':8,
'learning_rate': 0.01,
'feature_fraction': 0.5,
'bagging_fraction': 0.8,
'bagging_freq': 12
}
lgb_train = lgb.Dataset(train.drop(target, 1), train[target])
model = lgb.train(lgb_params, lgb_train)
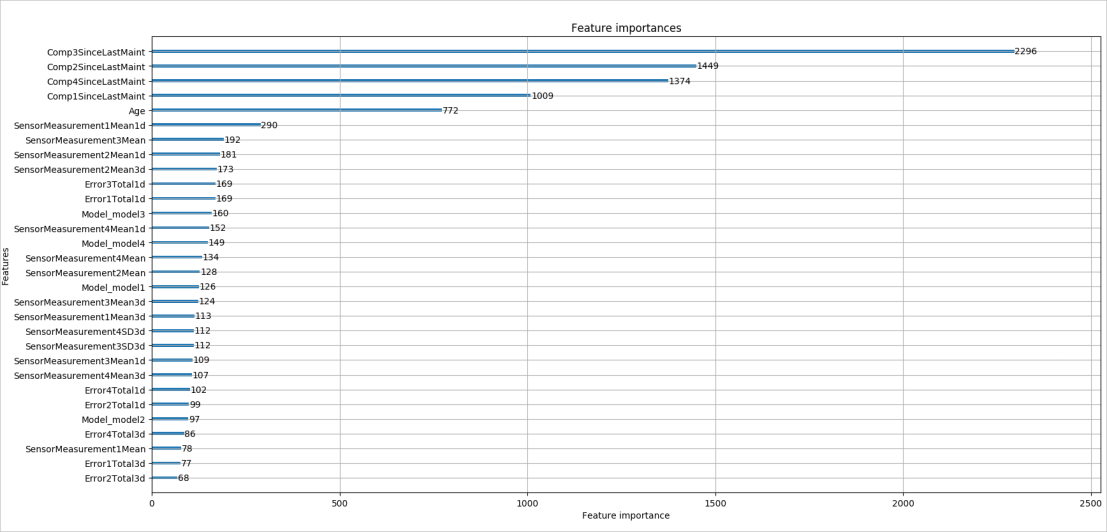
After the model is trained, we can then call the plot_importance function of the trained model to get the importance of the features.
plt.figure(figsize=(12,6))
lgb.plot_importance(model, max_num_features=30)
plt.title("Feature importances")
plt.show()

One thought on “Evaluate Feature Importance using Tree-based Model”