Introduction
One requirement I have been recently working with is to run R scripts for some complex calculations in an ADF (V2) data processing pipeline. My first attempt is to run the R scripts using Azure Data Lake Analytics (ADLA) with R extension. However, two limitations of ADLA R extension stopped me from adopting this approach. Firstly, ADLA R extension supports only one input dataframe and one output dataframe at the time when I write this blog post. However, the requirement I am working with needs the R scripts to take multiple dataframes as input and output multiple result dataframes. Secondly, the total size for the input and output is limited to 500 MB.
Another attempt I have taken was to create an ADF custom activity to execute the R scripts in Azure Batch Service. This option turns out to be a pretty flexible, easy to implement and manage approach.
Approach
This blog post highlights the key steps to implement this approach and also mentions the lessons I have learnt.
Step 1 – Preparing Azure Batch Service
Firstly, we need to add an Azure Batch pool in an Azure Batch service instance. If the Azure Batch service instance doesn’t exist yet, a new instance needs to be provisioned. Please refer to Microsoft official docs for the details on creating Azure Batch service and pools.
While adding the Azure Batch pool, we need to specify the VM image to provision as the computing nodes in the pool. We can use Data Science Virtual Machine image which ships with most of common R packages.

Step 2- Creating Container in Azure Blob Storage to Host R Source Files and Input/Output Data
Create a Blob storage container in your Azure Storage account and then create an Input folder and an Output folder within the container root folder.
The R source files will be deployed into the container root folder. The input data files are the output of the upstream process activities in the ADF pipeline and pushed (copied) into the Input folder. The R source files and the input data files will be submitted to execute in the Azure Batch service (by the Azure Batch custom activity which will be created later in the ADF pipeline), the output will be written into the Output folder in the Azure Blob storage.
Step 3 – Authoring R Scripts to Communicate with the Azure Blob Storage
When the Azure Batch custom activity is triggered in the ADF pipeline, the R source files and the input data files will be submitted into the work directory created for the submitted task on the Azure Batch computer nodes. The R scripts will load the data in the data files into dataframes, run the calculations and transformations, and finally write the results to output data files and store them in the work directory. The output data files will then be written into the Output folder in the Azure Blob storage using the blob operation functions provided by rAzureBatch package. Here is a good sample from the doAzureParallel Github site on the blob operations with rAZureBatch.
Basically, we need first to create a rAzureBatch StorageServiceClient with the Azure Storage account credentials.
storageCredentials <- rAzureBatch::SharedKeyCredentials$new(
name = "{name of the Azure Storage account}",
key = "{access key of the Azure storage account }"
)
storageClient <- rAzureBatch::StorageServiceClient$new(
authentication = storageCredentials,
url = "{url of the Azure Blob storage}"
)
Then, we need to create a SAS token with write permission on the Output folder
writeSasToken <- storageClient$generateSasToken(permission = "w", "c", path = {the path of the Output folder})
Lastly, we can save the output file into the Output folder on Azure Blob storage with the uploadBlob function.
response <- storageClient$blobOperations$uploadBlob(
containerName,
fileDirectory = "{output file name}",
sasToken = writeSasToken,
accountName = storageAccountName)
if (response[['status_code']]!=201) {
stop('Failed to save the output file.')
}
It is important to explicitly check the response status_code and throw error when the save action is failed. Otherwise, the ADF pipeline will not able to capture the error but instead treat the custom activity as running successfully and move on to the downstream activities.
Step 4 – Setup Azure Batch Custom Activity in ADF Pipeline
After the Azure Batch service part of work is done, we need to add and configure the Azure Batch Custom Activity in ADF Pipeline. This step is pretty straightforward, please refer to the Microsoft official docs for the more details. The only part needs to note is the settings of “Command” and “Folder path” of the Azure Batch Custom Activity. The “Command” should be “RScript {the entry R file you want to run}”, and the “Folder path” should be the container we have created earlier to host the R source files.

Those are the four main steps to setup the execution of R scripts in ADF pipelines.
Below lists a few of tips that might be helpful:
If you need to install additional R packages for your scripts, specify the lib path with the environmental variable, AZ_BATCH_TASK_WORKING_DIR, in order to install the packages into the working directory of the current task. Please refer to my previous blog post for further explanation.
install.packages("tidyselect", lib=Sys.getenv("AZ_BATCH_TASK_WORKING_DIR"))
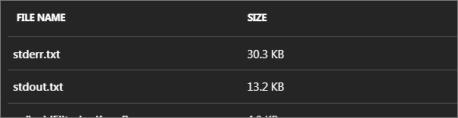
If the Azure Batch Custom Activity throw an UserError with message as “Hit unexpected expection and execution failed.”, you can find the detailed error message from the stderr.txt file on the working directory of the failed task.

To access the working directory, you need to go to the Azure Batch account –> Jobs –> select job –> select the failed task, and select “Files on node”.
Then you should be able to see all the files existing on the working directory of that task, including the stderr error output file.

Hello there. Very nice post!
Within your R script, how do you reference your input files that you use for your calculations?
Thanks!
Thanks so much Linxiao !! This was such a helpful post, saved me a lot of time. Approximately ho wlong does it take for this job to finish, my pipeline is ‘in progress’ for a long time. I will troubleshoot, but just curious.
Regards,
Poonam