When we process data using Pandas library in Python, we normally convert the string type of categorical variables to the Categorical data type offered by the Pandas library. Why do we bother to do that, considering there is actually no difference with the output results no matter you are using the Pandas Categorical type or the string type? To answer this question, let’s first take a simple test.
In this test, we create a data frame with two columns, “Category” and “Value”, and generate 50 millions rows in this data frame. The values of “Category” column are generated from a list of six predefined categories, [‘category1’, ‘category2’ … ‘category6’], and the values of “Value” column are generated from the list integer of [0 … 9].


We first time the execution of a group by operation against the “Category” column which is in the string type and also observe the memory usage of the “Category” column.

We then convert the “Category” column to the Pandas Categorical type, repeat the execution of the same group by operation and observe the memory usage of the “Category” column in Pandas Categorical type.

The result reveals a five times improvement on running speed and one eighth memory usage when converting the “Category” column to the Pandas Categorical data type.

This test result answers our original question that the reason to use Pandas Categorical data type is for the optimised memory usage and improved data processing speed. Then why does the Categorical data type have such magics? The answer is pretty simple, i.e. dictionary encoding.
If we open the source code of the Pandas Categorical class, we can see this class contains two properties, “categories” and “codes”.
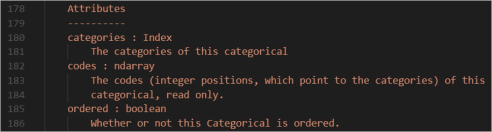
After we printed the two properties for the “Category” column used in our test, we can see the “categories” property stores the dictionary of the six categories available for the “Category” column and the actual category information of the “Category” column for all the rows in the data frame is stored in the “codes” property in the format of integer number which points to the position of the corresponding category in the “categories” property.
![]()

In this way, Pandas Categorical data type takes much less memory space to store the category information in integer type compared to store in the original string type. The query operations on the category column scan less memory space and therefore the time used on the query is shorten.
Dictionary encoding is a common technique used for data compression. For example, Azure Analysis Service and Power BI also used dictionary encoding in their Vertipad engine to compress data to reduce memory usage and to increase query speed.

